There are two reasons to optimize AWS Lambda functions performance. First is money – you pay for the Lambda execution duration. The quicker you do the job, the less you pay. The second is latency – the quicker you do the job, the shorter your client waits for the result. It’s a known fact that the decrease of latency improves sales, user engagement, and client satisfaction – so we could argue it’s also the money, in the end.
With this materialistic motivation, I invite you to discover several Lambda optimization techniques.
Increase memory
Lambda can have from 128 MB to 10 GB of memory. You pay for every Lambda execution plus its duration, calculated in GB-seconds. What is a GB-second? It’s assigned memory times duration. If a function has 1 GB of memory and runs for exactly 1 second, it’s 1 GB-second.
AWS measures the execution duration in milliseconds. Every optimization, if you execute Lambda on a big scale, can bring savings.
But going back to the memory. Proportionally to the memory, the CPU power is allocated. Doubling the memory size doubles the computation power.
What does that mean? With more memory (and CPU), our function can finish quicker. If we double the allocated memory, we also double the cost per millisecond, but the execution time can often be more than 2x shorter. This is an absolute win – lower latency for a lower price.

Execution time improvement, of course, depends on the used runtime and our code. You can find different benchmarks that show the execution time usually going down along with the memory increase until around 1-1.5 GB. That means assigning 10 GB of memory just to decrease latency to an absolute minimum is not a solution. Unless your goal is to throw money at AWS.
Then how to find the best balance between under- and over-provisioning of our Lambda? There are two solutions to automate it.
The first one is the open-source AWS Lambda Power Tuning. It’s a Step Function that runs your Lambda multiple times with different memory sizes to find the optimum settings. You can even include it in your CI pipeline to ensure your configuration is always optimal after any changes. And it produces a nice visualization!
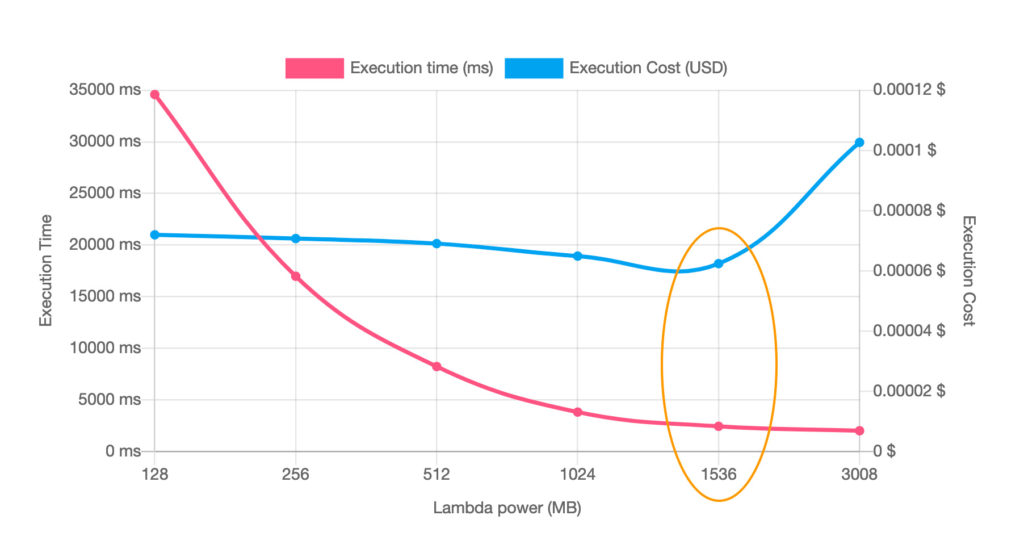
The second is AWS Compute Optimizer. When enabled, it will monitor your function and propose better settings on its own. It’s free.
From my experience – I start with 256 MB memory by default and then optimize it if the specific function takes too long or costs too much.
Use global state
A common misconception about the Lambda functions is that every execution happens in a pure, fresh environment, with no state passed from the previous invocations. After all, even AWS calls them stateless. We have the handler method, and that’s it.
Well, that’s not entirely true.
Lambda runtime environment is created for our function during the cold start (explained in deep a little bit further). Then every invocation triggers the handler function. The environment is reused for every following invocation. And we can make good use of it.
When we access the global state in the environment, we do not have to worry about concurrency. A single Lambda runtime is used for only a single invocation at the time.
One-time initialization
A typical pattern is to do all possible library and API clients’ initialization in the global scope. The most straightforward illustration of this is to create SDK clients outside of the handler function:
import {DynamoDBClient} from '@aws-sdk/client-dynamodb';
const dynamodb = new DynamoDBClient({});
export const handler = async (event, context): Promise<void> => {
// ...
};
This DynamoDB client instance will be created once per runtime and reused instead of being re-created with every Lambda run.
There is also a nice little profit of doing things outside of the handler – it’s free. Yes, we pay only for the execution time, counted from the moment your handler is invoked. The heavier stuff we can move outside, the bigger the profit – in both execution time of the following invocations and money. If you are determined enough, you can move a lot of workload into this gray but completely free zone.
Cache
We can use the global state for more than just the initialization. Since the runtime is reused, we can cache values in it.
If our execution requires obtaining SSM parameters, OAuth tokens, or even rarely-changing items from DynamoDB, there is no need to fetch them again in every invocation. Caching them will reduce not only our Lambda latency but also the bill for calling other services.
Implementing such cache is simple:
import axios from 'axios';
let token: string | null = null;
let tokenExpiration = Date.now();
const getToken = async (): Promise<string> => {
if (token === null || tokenExpiration < Date.now()) {
const response = await axios.get('https://example.com/auth');
token = response.data.token;
tokenExpiration = response.data.expiration;
}
return token;
};
For caching SSM values in Node.js, I personally use a small aws-parameter-cache package. It provides configurable cache behavior in one line.
Keep HTTP connections alive
Establishing HTTP connection takes time. Most calls we make in a Lambda function are to the same targets – APIs endpoints, external or AWS ones. We can save a significant amount of time creating the connection once and then reusing it.
For AWS SDK calls, we need to check the documentation to see if the underlying HTTP connection is kept alive. If not, we need to configure it ourselves. For example, in JS SDK v2, we need to set a special environment variable, but it’s enabled by default in the new JS SDK v3.
When making other calls, make sure to create the HTTP client once and configure it to reuse connections. For example, in Node, you can use the agentkeepalive package to create an appropriate HTTP Agent and use it with axios or any other library.
How much time can we save exactly? I run this simple Lambda 200 times, 100 with default HTTP Agent, and another 100 times with Keep Alive enabled:
import axios from 'axios';
import {HttpsAgent} from 'agentkeepalive';
const httpsAgent = new HttpsAgent({
timeout: 60000, // active socket keepalive for 60 seconds
freeSocketTimeout: 30000, // free socket keepalive for 30 seconds
});
const keepAliveAxios = axios.create({
httpsAgent: httpsAgent,
});
let cold = true;
export const handler = async (event: { keepAlive: boolean }): Promise<void> => {
const client = event.keepAlive ? keepAliveAxios : axios;
const start = process.hrtime.bigint();
await client.get('https://reqres.in/api/users/1');
const end = process.hrtime.bigint();
console.log(JSON.stringify({
cold: cold,
keepAlive: event.keepAlive,
time: Number((end - start) / 1_000_000n),
}));
cold = false;
};
Since the log message is a JSON, we can easily aggregate results with CloudWatch Logs Insights:
filter cold = 0
| stats count(), avg(time) by keepAlive

As we can see, for this particular external API the average latency difference with and without HTTP Keep Alive is 40 ms.
Cold starts
One of the things everyone seems to worry about with Lambda functions is the cold start. In most cases, they probably worry more than it’s worth. 500 ms of extra latency for several in a thousand executions in most cases is not a thing to bother with.
But anyway, cold starts. What are those? It’s best presented on this slide from the re:Invent:
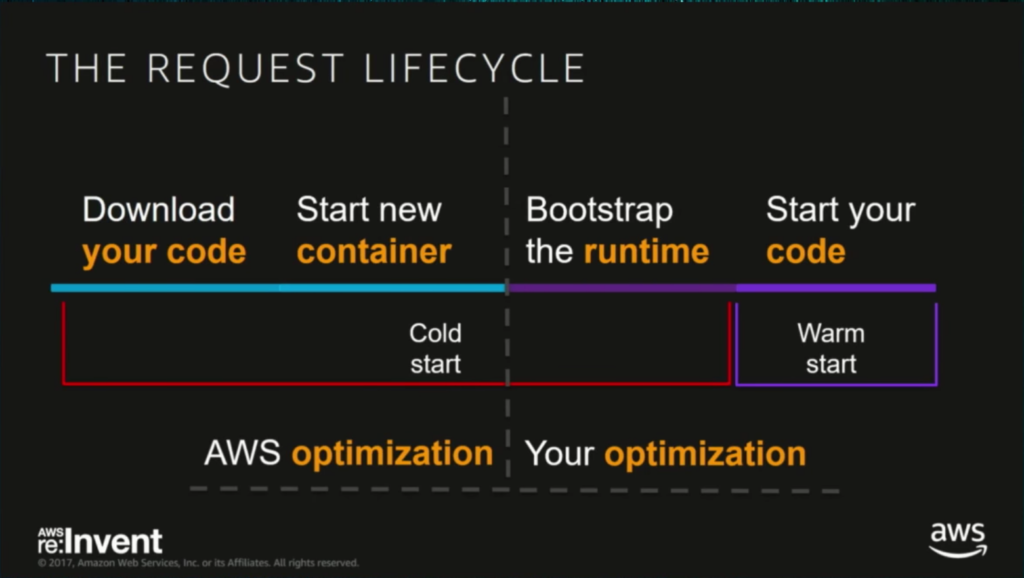
Deployed Lambda code lies in the S3 bucket. When we execute the function for the first time, Lambda downloads the code from the bucket, creates a new environment, initializes the runtime, and finally calls the handler function, passing the client’s request to it.
On the subsequent executions, everything is already prepared, so the handler gets called instantly.
As you can see, we have 3 operations that together sum up for the cold start.
When they happen
The cold start occurs every time the Lambda needs to create a new, fresh runtime. An obvious case is when we trigger the function to run for the very first time. But there are also others.
Firstly, the created environment is not kept indefinitely. It will be removed 5 to 15 minutes after the last function execution. The next invocation will have a cold start.
Secondly, the Lambda will scale up when needed to handle increased traffic. Scaling up means creating new environments to handle more requests in parallel. Each new environment is created in the same way as the first one, causing a cold start for this lucky request that triggered the scaling.
And finally, when we do changes in the Lambda configuration, like uploading new code or modifying environment variables, all existing environments are removed. Thus next requests will have a cold start.
Now, knowing all this, we can look at how to reduce the cold start time.
Decrease bundle size
I will start with disagreeing with the slide I put above. The “download your code” stage is labeled as “AWS optimization”, while it’s not completely true.
The time that it takes to download our code bundle from the S3 depends, at least partially, on its size. This is a part with which we can definitely do something.
For the Node.js environment, do not zip and upload the whole node_modules with all your dependencies, along with your own code.
Use a bundler like webpack
that will minify the code and do a tree shaking to include only those parts of your dependencies that you actually use.
For other platforms, if tree shaking is not possible, start with removing unnecessary dependencies. Sometimes you include a meta-package as a dependency, while instead, you can use just one of two concrete packages.
When using Serverless Framework, tell it to package each function separately, instead of creating a single bundle with all the code and all dependencies of all functions:
package:
individually: true
Don’t choose Docker
I always say that it’s important to choose the right tool for the job. Even when the world seems to choose JavaScript as the right tool for everything.
Despite that, if you want to reduce the cold start, your selection of the runtime makes a difference. This recent analysis done by Mikhail Shilkov clearly shows this dependence:
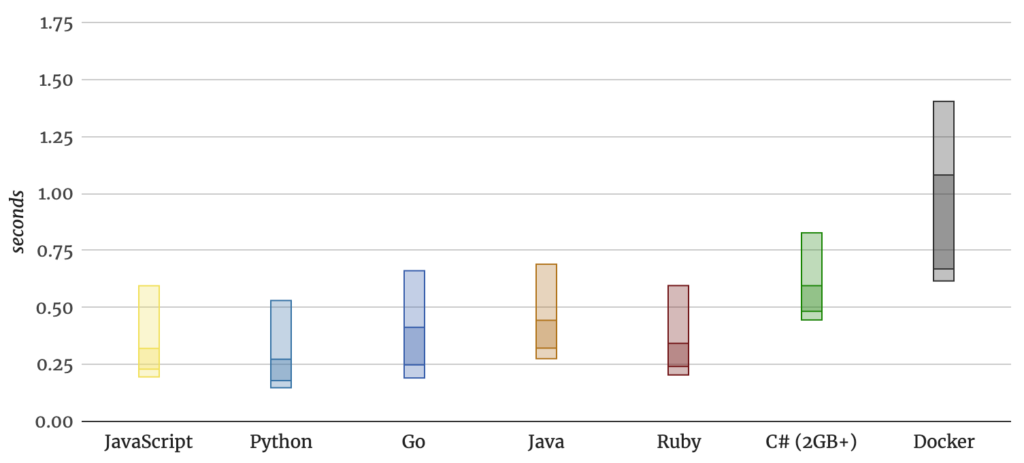
The Python, Node, and Ruby Lambdas bootstrap fastest. Java and Go are right behind them. But .Net and Docker… Well, while everyone is super enthusiastic about the ability to run the containers on Lambda, I would prefer to keep the cold start around 300 ms, not 1 second.
Running container images on the Lambda is a new feature, so there is a chance it will improve over time. I really hope for it.
Keep it warm
If we really, really, REALLY need to, we can keep functions warm to eliminate the cold start impact on the clients’ requests. Of course, we need to provision an appropriate number of environments, accordingly to the expected usage.
There are few options for that. We can use something like Serverless WarmUp Plugin or Provisioned Concurrency.
If you do so, remember to ask yourself – is this still serverless? And is it how serverless should look like?
But let’s be honest, sometimes we need it. I once had a Lambda with the sharp library for image conversion, and the cold start took around 2 seconds. Normally I probably wouldn’t care, but here it was generating a response to a Slack Event and had to complete under 3 seconds. Keeping the Lambda warm was the only solution.
Summary
If you have any other suggestions and patents for optimizing Lambda functions, please share them in a comment.

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.