The new version of AWS SDK for JavaScript / TypeScript / Node.js came with a few significant improvements. But does “General Availability” mean “ready for the production”? How to use it? And how to unit test our code using it? Let’s take a look at it.
As with every major version, there are breaking changes, but also cool new features. Let’s start with what’s different on the high-level. Then we will continue with how to use the new AWS JS SDK v3.
To use it on production, we need a good way of mocking it for unit tests. This is why I created a specialized mocking library that I show at the end.
Architecture
Written in TypeScript
More and more of the JavaScript world becomes, in fact, a TypeScript world. This is happening on both the frontend and the backend side.
The previous SDK had built-in typings to allow usage with TypeScript, but it was written in pure JavaScript. Unlike it, the new AWS JS SDK v3 is created entirely in TypeScript and then transpiled to JavaScript.
As a result, we should get better type-checking and code-completion suggestions. In most IDEs, this will also work for pure JavaScript.
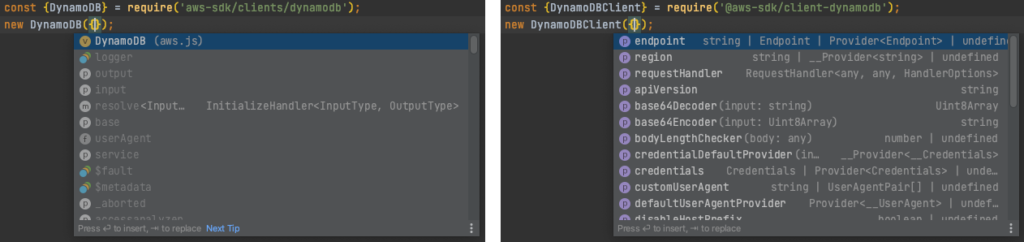
Modularized
How it was
In v2, you installed the whole AWS SDK with a simple:
npm install aws-sdk
Then you had two options regarding importing the library and creating clients. An easy one and a good one.
The easy one:
import {DynamoDB} from 'aws-sdk';
const dynamodb = new DynamoDB();
The good one:
import DynamoDB from 'aws-sdk/clients/dynamodb';
const dynamodb = new DynamoDB();
The difference is in the import path. If you used some bundler like webpack to package the code, it tried to do tree-shaking. What’s a tree shaking? It’s removing the unnecessary code from the final package, reducing its size. That is a good thing for the frontend, but also for the Lambda functions, where smaller package = smaller cold start.
The tree shaking is done based on the import paths.
If you import something, the bundler treats it as used and does not remove it.
So in the “easy one” approach, we tell that we are using the whole aws-sdk library, while in the “good one”, we specify usage of only the dynamodb module.
Result? With just a difference in the import style, the Lambda zip package size changes from 1.3 MB to 389 KB.

How it is
Now, with v3, you don’t have to remember to use the proper import path. Instead, you must install each Client you want to use as a separate dependency:
npm install @aws-sdk/client-dynamodb
That will install only the DynamoDB Client and several common packages.
Even if you don’t use any bundler and add the whole node_modules directory to the Lambda package, its size will be smaller.
The drawback is that we need to specify each Client library separately in the dependencies. Also, we need to configure each Client independently (by setting a region, etc., if required). Removing common, global configuration, however bad may seem, was done to resolve some frequent issues.
Middleware Stack
AWS JS SDK v3 introduces a new way to intercept and potentially modify requests and responses. The mechanism for that, adding middleware layers, should be familiar to anyone who worked with the Node.js Express framework. It is broadly used internally to build our requests, but we have access to it as well. Intercepting SDK calls is something we will rarely need to do in real life, but you never know when having this ability may come in handy.
As a simple example, we can add a middleware that will log all the SDK requests:
const dynamodb = new DynamoDBClient({});
dynamodb.middlewareStack.add(
(next, context) => async (args) => {
logger.info('Sending request from AWS SDK', {request: args.request});
return next(args);
},
{
step: 'finalizeRequest',
name: 'logCalls',
}
);
With the logger here being a nicely configured library
serializing objects to JSON, this is the log we will see in the CloudWatch for a ListTablesCommand:
{
"level": "info",
"message": "Sending request from AWS SDK",
"request": {
"method": "POST",
"hostname": "dynamodb.eu-west-1.amazonaws.com",
"query": {},
"headers": {
"content-type": "application/x-amz-json-1.0",
"x-amz-target": "DynamoDB_20120810.ListTables",
"content-length": "2",
"host": "dynamodb.eu-west-1.amazonaws.com",
"x-amz-user-agent": "aws-sdk-js/3.8.1 os/linux/4.14.214-164.339.amzn2.x86_64 lang/js md/nodejs/12.20.1 api/dynamodb/3.8.1 exec-env/AWS_Lambda_nodejs12.x",
"user-agent": "aws-sdk-js/3.8.1",
"amz-sdk-invocation-id": "0221a1ba-fe3f-4a4d-85dc-867878e92b45",
"amz-sdk-request": "attempt=1; max=3",
"x-amz-date": "20210315T181313Z",
"x-amz-security-token": "...",
"x-amz-content-sha256": "44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a",
"authorization": "..."
},
"body": "{}",
"protocol": "https:",
"path": "/"
}
}
You can read more about adding and configuring middleware in this AWS blog post.
Changes
Sending Commands
This is probably the most visible change, as creating and sending commands is now much different.
With SDK v2, the most common approach was to utilize the async/await style:
import DynamoDB from 'aws-sdk/clients/dynamodb';
const dynamodb = new DynamoDB();
export const handler = async () => {
const tablesResponse = await dynamodb.listTables({
Limit: 10
}).promise();
};
To refactor it to SDK v3, we need to know about two main differences:
- the new Client has a
send()method that consumes the Command objects we need to create, - the
send()method returns a promise – without any additional calls.
The same operation in AWS JS SDK v3 will be:
import {DynamoDBClient, ListTablesCommand} from '@aws-sdk/client-dynamodb';
const dynamodb = new DynamoDBClient({});
export const handler = async () => {
const tablesResponse2 = await dynamodb.send(new ListTablesCommand({
Limit: 10
}));
};
Is it better or worse? Different. The option to create a command and pass it further as an object will surely be helpful in some cases.
To ease the migration, SDK v3 also supports the “old-style” calls. But you must be aware that it’s not recommended approach.
HTTP keep-alive
Did you know that with AWS JS SDK v2 and a code like this:
import DynamoDB from 'aws-sdk/clients/dynamodb';
const dynamodb = new DynamoDB();
await dynamodb.listTables().promise();
await dynamodb.deleteTable({
TableName: 'my-table'
});
the HTTP connection is, by default, closed and re-created for every separate call? Establishing the connection takes time, increasing latency. In fact, for many SDK calls opening the connection could take longer than the rest for the call itself. If you have a Lambda function making a few SDK calls, that time may be a large part of the total execution time.
Of course, in SDK v2, you could change this behavior.
You have to either set a special AWS_NODEJS_CONNECTION_REUSE_ENABLED=1 environment variable or create and configure HTTP Agent used by the SDK.
The performance benefits could be tremendous.
But not everyone knows this.
Fortunately, this is no longer a case in AWS JS SDK v3. Now the HTTP connection used by AWS SDK is kept alive by default.
S3 object body
This is a poorly documented change that causes some people to think that the SDK no longer returns the object content from the S3 buckets. It does, but reading it is a little bit harder than it was.
To read a text file stored in S3, with AWS JS SDK v2, you did this:
import S3 from 'aws-sdk/clients/s3';
const s3 = new S3();
const resp = await s3.getObject({
Bucket: 'my-bucket',
Key: 'file.txt',
}).promise();
const bodyContents = resp.Body?.toString();
The returned Body was a Buffer, and reading it, as you see, is not particularly complicated.
Now, in AWS JS SDK v3, the Body is a ReadableStream. That allows processing the object as a stream without reading it whole to the memory at once.
For big objects – that’s great.
But for small ones, with which we are OK to read them at once, we still have to process the ReadableStream. And this is slightly more complex.
Firstly, we execute a command to get the object:
const s3 = new S3Client({});
const response = await s3.send(new GetObjectCommand({
Bucket: 'my-bucket',
Key: 'file.txt',
}));
As posted here, now we can read the stream with this “simple” function:
import {Readable} from 'stream';
async function streamToString(stream: Readable): Promise<string> {
return await new Promise((resolve, reject) => {
const chunks: Uint8Array[] = [];
stream.on('data', (chunk) => chunks.push(chunk));
stream.on('error', reject);
stream.on('end', () => resolve(Buffer.concat(chunks).toString('utf-8')));
});
}
const bodyContents = await streamToString(response.Body as Readable);
If you, like me, don’t think adding this boilerplate code to every project that uses S3 is a great idea, you can use the get-stream library and do it in one line instead:
const bodyContents = (await getStream.buffer(response.Body)).toString();
There is an ongoing discussion about providing some additional options to read objects easily, without any low-level boilerplate code and extra dependencies.
Other changes
There are also other changes that you will find sooner or later.
When accessing the S3 bucket from another region, you need to create an S3 Client for that region – redirects are not followed automatically like in the v2 SDK.
In some commands, the Payload field is now an Uint8Array
instead of the string, both in requests and responses.
And undoubtedly other small changes.
But it’s a major release, so that’s expected.
Utilities
Pagination
This is the improvement I’m most happy about. I cannot count how many times I wrote a utility to fetch all the results from a paginated response. Or at least copied it from one project to another. The basic idea for pagination was always similar to this:
import DynamoDB from 'aws-sdk/clients/dynamodb';
const dynamodb = new DynamoDB();
const items = [];
let hasNext = true;
let exclusiveStartKey = undefined;
while (hasNext) {
const results = await dynamodb.query({
TableName: 'my-table',
KeyConditionExpression: '...',
ExclusiveStartKey: exclusiveStartKey,
}).promise();
results.Items && items.push(results.Items);
exclusiveStartKey = results.LastEvaluatedKey;
hasNext = !!exclusiveStartKey;
}
But no more, as now for all the commands that may require it, there are built-in pagination utility functions:
import {DynamoDBClient, paginateQuery} from '@aws-sdk/client-dynamodb';
const dynamodb = new DynamoDBClient({});
const queryPaginator = paginateQuery({client: dynamodb}, {
TableName: 'my-table',
KeyConditionExpression: '...',
});
const items = [];
for await (const page of queryPaginator) {
page.Items && items.push(page.Items);
}
As you can see, the paginate* utility uses Async Iterators
to get all results with short and readable code.
And it’s not only for DynamoDB.
You will find functions like this for other clients as well.
DynamoDB
The SDK v2 DynamoDB DocumentClient, which allows operating on the “normal” objects with automatic marshaling and unmarshalling, is available in v3 as well.
It’s in a separate module, @aws-sdk/lib-dynamodb.
To create it, you must first have a “regular” DynamoDB Client. Then operations are similar – you make a Command and send it.
import {DynamoDBClient} from '@aws-sdk/client-dynamodb';
import {DynamoDBDocumentClient} from '@aws-sdk/lib-dynamodb';
const client = new DynamoDBClient({});
const ddbDocClient = DynamoDBDocumentClient.from(client);
await ddbDocClient.send(new PutCommand({
TableName: 'my-table',
Item: {
id: '1',
content: 'lorem ipsum',
},
}));
Interestingly, you can also customize marshaling and unmarshalling options.
There is also a @aws-sdk/util-dynamodb module
that provides marshall() and unmarshal() functions if you need to do it on your own.
Storage
Another high-level library, and the only other one at the moment, is @aws-sdk/lib-storage. It comes with a single class that provides an easy way to do multipart upload to the S3 bucket.
Problems
No X-Ray wrapper (yet)
To fully benefit from the X-Ray, you need to instrument your code and AWS calls. Only then will you see the interactions between your Lambda and other services.
At the moment, the X-Ray SDK for Node.js does not provide a wrapper for JS SDK v3. But this seems to be under development and hopefully be released soon.
Bugs
The SDK v3 is in a Generally Available, stable version. But being “stable” does not equal “without bugs”, only without “breaking API changes from now on”. And there are bugs.
Looking at the list of open bug tickets, 48 of them at the moment I write this, it is not bad. Not all of them are actually errors but rather misunderstandings of the changes. Others relate to the build process or specific environments. For others, there are workarounds.
But some commands do not work correctly.
Mostly there are issues with specific parameters, but not only.
For example, the ApiGatewayManagementApiClient, used to send WebSocket messages to connected API Gateway clients, is broken completely. In such a case, the only solution is using the SDK v2 for this operation until it’s fixed.
Mocking for Unit Testing
If none of the Clients you use is broken, there is still one more thing before you can go to production with the new SDK. You need the ability to write unit tests for the code that uses it. And would be best if mocking the SDK would not be overcomplicated.
For the old SDK, you could do this with a popular aws-sdk-mock library.
I needed the same ability for the AWS JS SDK v3 before deciding to switch to it. There was a thread with some ideas on how to mock calls, but with an SDK consisting of so many Clients and Commands that we can send, I needed something powerful and uncomplicated to set up in the next projects. And for sure without any boilerplate.
As I love trying new things and the latest releases and didn’t want to wait for someone else to come up with a good mocking library, I created one myself:
The objectives I had:
- provide a fluent interface to declare mock behaviors in a short, easy, and readable way,
- give the ability to match behaviors by Command type and/or its input payload,
- use TypeScript for the same code-completion suggestions and type control as in the regular production code,
- make it work with any testing framework.
And I think I accomplished all of the above pretty well! This is how it looks like in action:
AWS SDK v3 Client mock library
An example from the README shows how can you match the mock responses based on the sent Command:
import {mockClient} from 'aws-sdk-client-mock';
const snsMock = mockClient(SNSClient);
snsMock
.resolves({ // default for any command
MessageId: '12345678-1111-2222-3333-111122223333'
})
.on(PublishCommand)
.resolves({ // default for PublishCommand
MessageId: '12345678-4444-5555-6666-111122223333'
})
.on(PublishCommand, {
TopicArn: 'arn:aws:sns:us-east-1:111111111111:MyTopic',
Message: 'My message',
})
.resolves({ // for PublishCommand with given input
MessageId: '12345678-7777-8888-9999-111122223333',
});
The lib is based on the Sinon.JS, and gives the ability to spy on the mocks as well.
If you are using the new AWS JS SDK v3, or plan to use it, make sure to check it out. And maybe leave a ⭐ on GitHub.
Further resources
Is the new SDK ready for production? Yes, I think so. And I use it. But make sure to test how your service behaves after the changes. And there may be places where you will still need to use the old one.
For more info and resources, visit the official Developer Guide. For a list of Clients and Commands, see the SDK docs. With any problems, search the GitHub issues first, as there are many helpful solutions there. And for unit testing, check out my Client mocking library.

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.