- Serverless
- Step Functions: HTTP request task
- Step Functions: redrive failed execution
- Step Functions: test step
- Lambda: much faster scaling up
- Lambda: future runtime launch dates
- Lambda: advanced logging controls
- CloudWatch Logs: cheaper log class
- CloudWatch Logs: pattern grouping
- CloudWatch Logs: anomaly detection
- CloudWatch Logs: query generator
- DynamoDB: zero-ETL OpenSearch integration
- DynamoDB: zero-ETL Redshift integration
- AppSync: easier Aurora Data API integration
- ElastiCache Serverless
- SQS: FIFO throughput increase and DLQ redrive
- S3: Express One Zone storage class
- OpenSearch Serverless: vector engine
- Integrated Application Test Kit
- Not Serverless (but still interesting)
- Aurora: Limitless preview
- OpenSearch: direct S3 queries
- AWS SDK for Rust and Kotlin
- Cost Optimization Hub
- myApplications
- CloudWatch: Application Signals
- Q: the AWS AI
- Form 1: generative AI service
- Form 2: AWS AI assistant
- Form 3: troubleshooting helper
- Form 4: context-aware query generator
- It’s still the preview
- Conclusion
AWS re:Invent 2023 ended, so let’s look at the most interesting announcements for serverless and more. There are exciting features to try and, maybe more importantly, features to avoid!
Looking at the announcements, I think we are entering the next era for serverless and cloud computing in general. There are fewer groundbreaking new services or big features. Instead, there are more quality of (developer) life improvements. Enough to say that four of the announcements below are about CloudWatch Logs.
And that’s a great thing. It means that things are stable and most capability gaps are closed, so we can focus on building our solutions on top instead of making workarounds (in most cases, at least).
That doesn’t mean there were no important updates. For me, Step Functions and CloudWatch Logs teams are winning this re:Invent in terms of the best improvements and new features.
Okay, let’s see what’s new.
Serverless
Step Functions: HTTP request task
The new task type allows you to make HTTP requests directly from the Step Function. No more need for a Lambda function to make an external API call.
What’s best is that it’s really versatile. Instead of creating integrations with specific API partners, the Step Functions team lets you connect to almost any API. You can set the request method, body, headers, and query parameters and even encode the body in the x-www-form-urlencoded form.
There are some limitations, sure – the request body must be provided as JSON, and not all headers are allowed.
So no XML or SOAP requests, but I don’t think that’s a big issue, even though I still integrate with such APIs occasionally.
An interesting design choice is using EventBridge Connections for authorization. That makes sense – it’s already in place and supports basic auth, API keys, and oAuth. But don’t be afraid; it does not use EventBridge API Destinations, so there is no 5-second timeout limit (although I could not find any specific timeout mentioned).
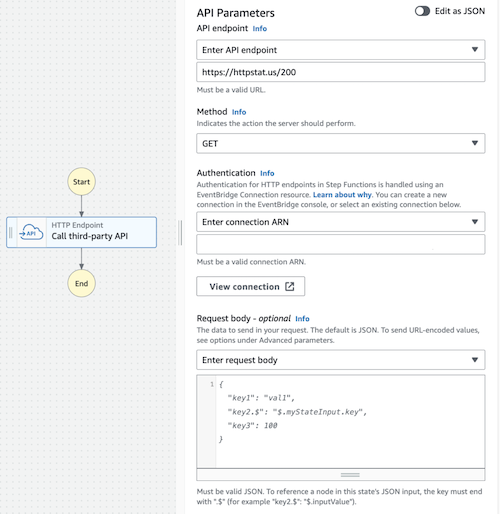
My opinion: Easily top #1 re:Invent announcements for me. My only issue is Secrets Manager, which you must use for secrets when creating EventBridge Connection. While EventBridge then makes its own copy of the secret, which is free with no charges for using it, the original one still costs flat $0.40 per secret to store a few bytes of API key.
My reaction: I’m loving it 😍
See more: announcement post
Step Functions: redrive failed execution
Step Functions execution failed in the middle because of an external error and now you have to re-run the whole process? Not anymore. You can redrive execution starting from the failed state. Important to know is that the redrive will run on exactly the same Step Function definition, so you can’t modify Step Function and re-run the failed step using the new, fixed workflow version.

My opinion: It’s never the fault of our code, right? But jokes aside, it’s very useful.
My reaction: SF team admiration 🤗
See more: announcement post
Step Functions: test step
Developing and testing Step Functions can be annoying when you make changes, run execution, wait for it to reach your modified state, see errors, fix, rerun the whole thing… You get what I mean. Wouldn’t it be great if you could run an individual state to test it?
Well, now you can. You can select and run a state in the Step Function edit view, providing only the state input. What’s great is you get very detailed, step-by-step (you see what I did here?) logs on input/output processing. This will allow you to catch all problems like missing IAM permissions, incorrect result selectors, etc.
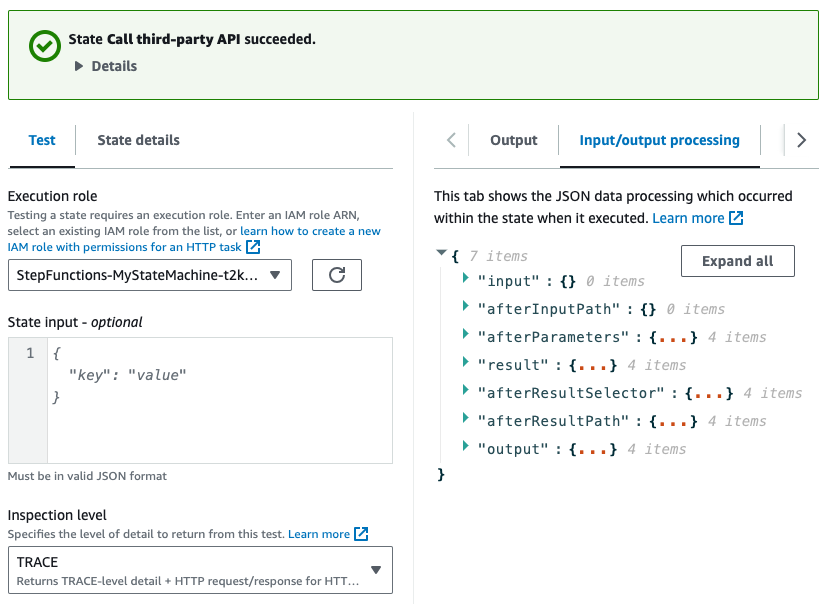
My opinion: Total saved developer-hours of Step Functions users will be counted in thousands.
My reaction: amazed 🤩
See more: announcement post
Lambda: much faster scaling up
Before, when handling increased traffic, Lambda would scale up by creating up to 500 to 3,000 new execution environments in the first minute (depending on the region) and an additional 500 environments every minute. Moreover, those scaling quotas were shared by all Lambda functions in the account region.
Now, it can scale up by 1,000 environments every 10 seconds. That’s… much faster. And each function is scaled independently, meaning each of your Lambda functions can create up to 1,000 new environments every 10 seconds.
There is still the limit of total account concurrency. The default quota for Lambda concurrent executions is 1,000, and even lower for new accounts. But you can request it raised to “tens of thousands”.
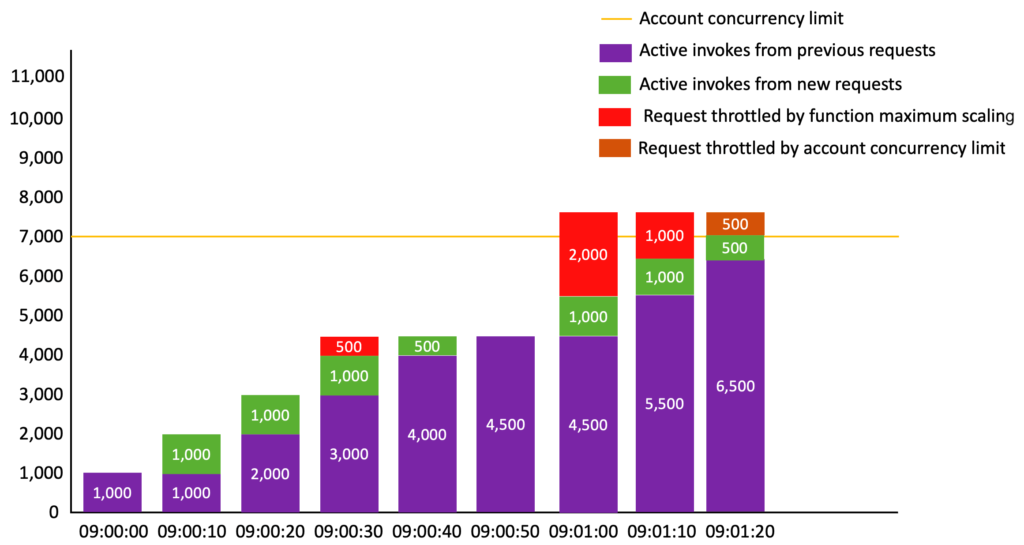
My opinion: That’s great. And you don’t have to do anything to benefit from this.
My reaction: positively shocked 😲
See more: announcement post, docs
Lambda: future runtime launch dates
Next to Lambda runtime deprecation dates, the AWS docs now include the target dates for the new runtime version releases.
My opinion:
Why is it so important I put it on the list? Because if I’m tired of people constantly asking “when Python x”, “when Node y”, then the AWS Lambda team must be fed up, too.
Also, since we’re on this subject, I don’t think people understand that adding a new runtime version is for AWS more than wget https://nodejs.org/en/download/the-latest-node-version.zip and it also includes a commitment to maintenance for extended time for tens of thousands of clients.
So people asking for the new runtime on the same day as its release are, frankly, delusional.
Also, AWS already improved the runtime upgrade cycle. Now, with this added transparency on the expected release dates, I’m totally satisfied.
My reaction: relieved 😮💨
See more: docs
Lambda: advanced logging controls
You can now select JSON log format for Lambda function and use language-default logging tools, like Node.js console object
and Python logging module, to log messages in structured JSON format. When using it, you set the log level in Lambda settings, which is a nice improvement over a standard environment variable.
Additionally, system logs like START, END, and REPORT are also logged as JSON.
Another feature of advanced logging controls is setting a custom log group instead of the auto-generated one, which can be helpful if you want to aggregate logs from multiple functions in a single place.
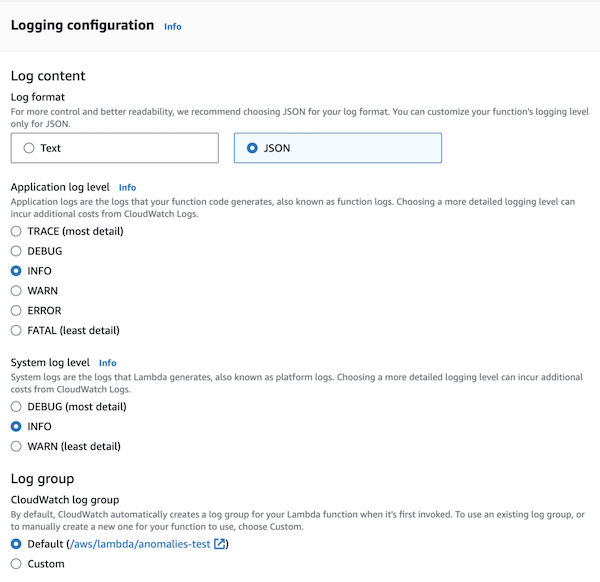
My opinion: Initially, I was ecstatic – no need for added dependencies for the logger! Then I tested it. On Node.js, the extra parameters added in the standard way are inlined as string, not JSON fields. On Python, the DEBUG log level includes logs from boto3, and there is a lot of them. A big no-no for me. I’m continuing logging as JSON with logger libraries, which also provide features like log sampling.
My reaction: big sad 😭
See more: announcement post
CloudWatch Logs: cheaper log class
CloudWatch Logs, with $0.50 per GB of ingested data, can quickly become one of the top costs for serverless applications. That’s why it’s essential to follow some best practices.
Now, however, you can choose the Infrequent Access log class for your Log Group and pay only half the price for the ingest – $0.25 per GB. There are, obviously, tradeoffs – not all features are available with Infrequent Access. You can’t create subscription filters, export to S3, use Live Tail, Lambda Insights, the new Anomaly Detection, or use metric filtering or embedded metric format for creating metrics from logs. Additionally, you can see them only through Logs Insights, not the regular log group stream view, so the cost for reading logs is $0.005 per GB of data scanned.
My opinion:
The lack of CloudFormation support for now makes it only a theoretical feature for any IaC (unless you want it very much and use custom resources to create it on your own). The CDK may be the first to support it since it creates Lambda Log Groups programmatically anyway.
Apart from that, if you don’t need any of the unsupported capabilities, it’s definitely worth considering, especially for the production environments.
My reaction: mixed feelings 🥲
See more: announcement post
CloudWatch Logs: pattern grouping
In CloudWatch Logs Insights, all logs are now additionally grouped in automatically recognized patterns. “Patterns” are similar logs that differ only in some values, like dumped variables. Which makes total sense because there is usually only a limited set of different log types your application writes.
With patterns, it’s much easier to find unusual or alarming logs – instead of traversing hundreds of log messages, you only look at a few aggregated types of log messages. You can click on any of them to see all matching logs. Additionally, you can compare patterns with different periods to see if the number and ratio of log types changed or not.
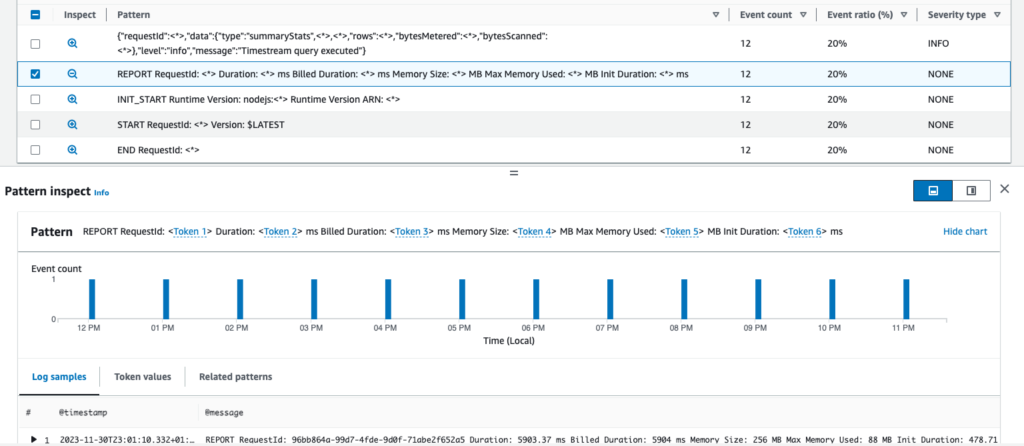
My opinion: It’s one of those features you wonder how you could lived without for so long. And you get this for free (no additional cost apart from the regular price of CloudWatch Logs Insights), which is a cherry on top.
My reaction: simply amazed 🤩
See more: announcement post
CloudWatch Logs: anomaly detection
You can now enable anomaly detection on CloudWatch Log Group. After a short learning time, it will automatically, well, detect anomalies in your logs. Anomalies are based on automatically recognized patterns (similar to those described above) and changes in their frequency. When enabled, CloudWatch will detect changes like a decreased number of success logs, an increased number of warning or error logs, or even a lack of logs, meaning your Lambda stopped being invoked (yes, I had to create such alarms in the past).
You can temporarily or permanently suppress types of findings, which is very useful.
To get notified of new anomalies, you need to create a CloudWatch Alarm. Apart from that, anomaly detection is free of charge (or rather – included in the data ingestion price).
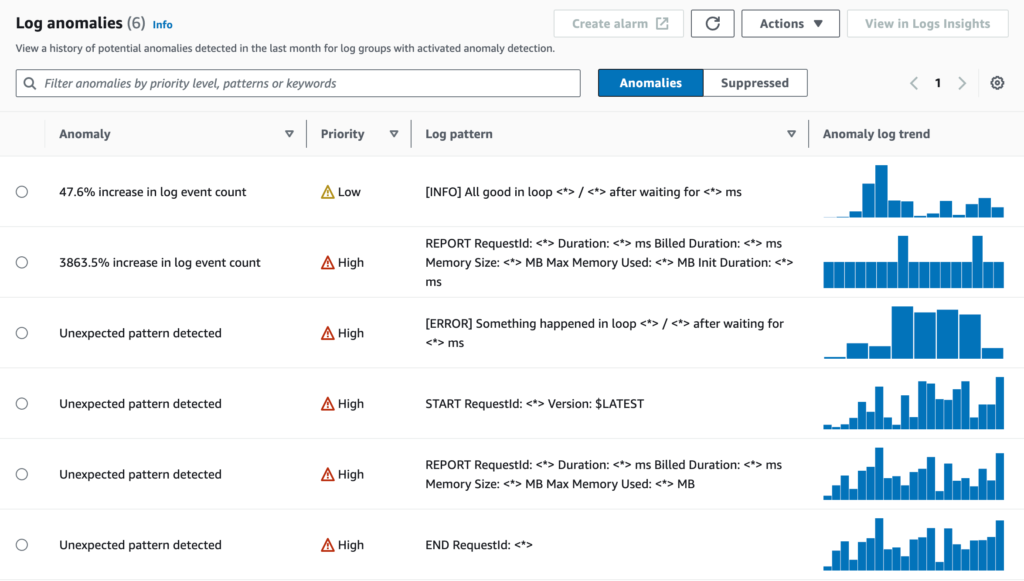
My opinion:
AWS announced pattern grouping and anomaly detection in a single blog post, but I think those two are big and important enough to be separate topics. I’ll definitely use both of those features on real production apps sooner rather than later.
With anomaly detection, the only problem may be the initial number of false positives, especially if you link it to a CloudWatch Alarm. And the fact we get this for no additional charge surprises me – in a good way, of course.
My reaction: simply amazed 🤩
See more: announcement post
CloudWatch Logs: query generator
While the CloudWatch Logs Insights query syntax is not overly complicated, I’m not using it frequently enough to learn it by heart like SQL. Therefore, the new query generator that converts natural language expressions like:
find 10 longest Lambda invocation times
into:
fields @timestamp, @message
| filter @type = "REPORT"
| stats max(@duration) as maxDuration by @logStream
| sort maxDuration desc
| limit 10
is really something.
Currently, the capability is in preview and available only in the us-east-1 and us-west-2 regions, free of charge.
My opinion: I’m not the biggest fan of Generative AI, simply because everyone is adding it everywhere even if it does not make sense, sometimes worsening instead of improving services. That being said, the query generator for Logs Insights is an example of AI applied correctly. I’m eager to put it to the test in real cases.
My reaction: interested 🧐
See more: announcement post
DynamoDB: zero-ETL OpenSearch integration
DynamoDB can now automatically ingest items to OpenSearch. You need to enable DynamoDB Streams and point-in-time recovery on the table, and the rest – both the initial data load and keeping it in sync – is handled for you. There is just one catch – it requires an OpenSearch ingest pipeline.
My opinion: Ingest from DynamoDB to OpenSearch is a common pattern to get a fast and scalable database with added search capabilities. The built-in integration that does not require a Lambda function in the middle is totally spot on. The only problem lies in OpenSearch ingest pipeline pricing, starting with a small amount of $170/month. While I see it as worthwhile on large applications, it’s unacceptable for serverless development and smaller services. Thus, I’m good with my Lambda functions for now…
My reaction: not even sad, just disappointed 😑
See more: announcement post
DynamoDB: zero-ETL Redshift integration
Similarly to OpenSearch integration, DynamoDB will be able to keep data in sync in Redshift.
The capability is now in limited preview, so it’s hard to say more about it. You can sign up for access.
My opinion: In my experience, it’s a less common pattern than ingest to OpenSearch, but a direct integration is still warmly welcomed. I just hope that, unlike the OpenSearch ingestion, it won’t introduce extra costs.
My reaction: cautiously interested 🧐
See more: announcement
AppSync: easier Aurora Data API integration
AppSync JavaScript resolver utils got support for making Aurora Data API requests with createMySQLStatement() and createPgStatement() helper functions.
The query can be provided as SQL or created with a builder.
Additionally, in AppSync, you can now generate the whole API from Aurora Cluster with a few clicks.
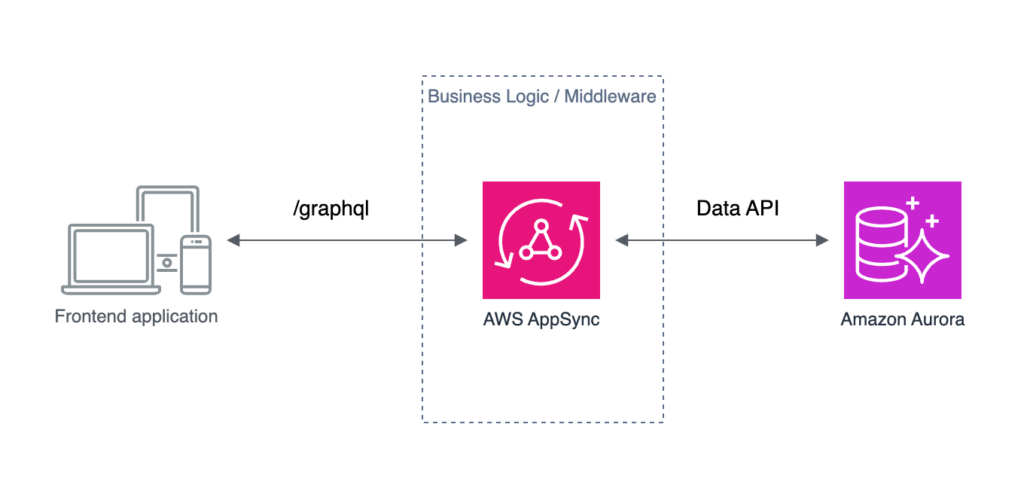
My opinion: This sounds good until you realize that the Data API is still only supported by the Aurora Serverless v1, not v2. And that’s a big limitation because v1 does not scale well and is available only with a few not-so-recent Aurora versions. And since you could already make Data API calls from AppSync, this does not introduce any new real capabilities. Don’t get me wrong – helper functions are great, but with no support for Data API from Aurora Serverless v2, they are not worth much…
Update 2024-03-17: On December 21st AWS released support for the Data API for Aurora Serverless v2 and also Aurora provisioned clusters. However, at the time of writing, support is only for PostgreSQL and only in 4 selected regions. Meanwhile, AWS also announced the end of life for Aurora Serverless v1 on December 31, 2024.
My reaction: meh 😒
See more: announcement post, docs
ElastiCache Serverless
The new serverless version of ElastiCache is more expensive than the eight cheapest on-demand instance variants. But the pricing model is interesting because, unlike other expensive serverless services, here you don’t pay for always-on idle processing units but only for actual per-request usage. What generates costs is the data storage with a minimum billable value of 1 GB.
My opinion: While better than for OpenSearch Serverless, the pricing model is still unsuitable for serverless workflows with a $90/month minimum charge. DynamoDB is a better key-value storage for most new applications, so unless you migrate an existing system, have particular needs, or calculated significant cost savings, you will be better with DynamoDB by default.
My reaction: could be worse 🙄
See more: announcement post
SQS: FIFO throughput increase and DLQ redrive
SQS FIFO queues offer exactly-once processing and strict ordering. Of course, this comes at a price, and this price is limited throughput. While standard queues offer a “nearly unlimited number of transactions per second”, FIFO queues always had limits. But now, with the support for 70,000 transactions per second in high throughput mode, you have to try really hard to reach those limits.
Also, FIFO queues now support the Dead Letter Queue redrive option, allowing the re-delivery of messages that have not been processed.
My opinion: Sadly, I don’t work on any service requiring such a large throughput. However, it’s worth remembering that it’s possible only in the high throughput mode where messages belong to a uniform distribution of groups, and FIFO order is guaranteed only in the scope of a single group.
My reaction: nice 🙂
See more: announcement post
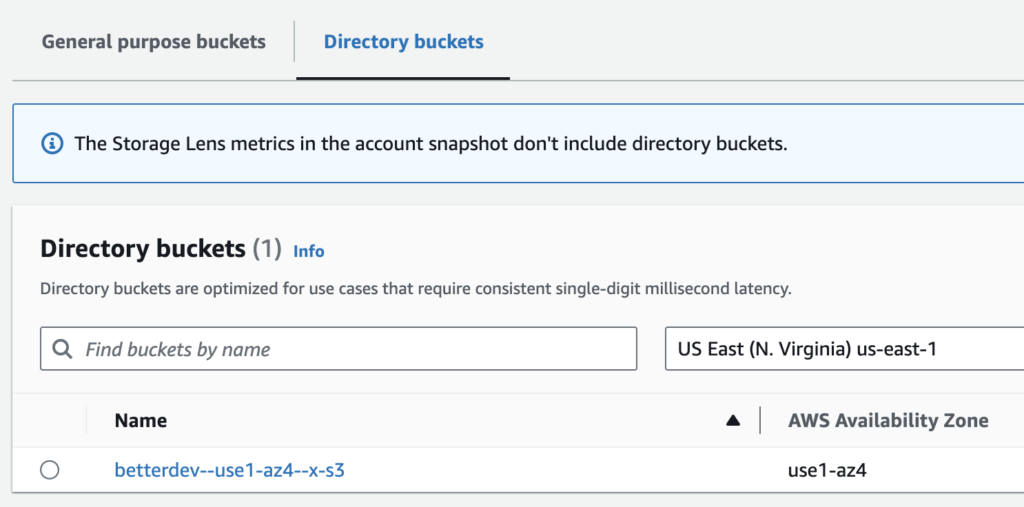
S3: Express One Zone storage class
The new S3 storage class, named Express One Zone, is created to handle “hundreds of thousands of requests per second with consistent single-digit millisecond latency”. What’s important is that this is a purpose-built storage that works best for small files with a short life span.
This storage is different enough from other S3 storage classes that it has a separate tab on the S3 page in the AWS Console.
Next to the “general purpose buckets”, those new Express One Zone buckets are under the “directory buckets” tab.
They have a special naming scheme and a new authentication method that grants access tokens valid for 5 minutes.
Furthermore, when listing objects, prefixes must be full directory names ending with /.
The main use case of Express One Zone buckets is to store intermediate files of data-intensive distributed computing, like AI/ML training. But I’m sure AWS customers will find many other applications.
My opinion: It’s a specific solution for a specific problem. Before you use it because “it’s faster”, “it has directories”, and “read and writes cost half the Standard class price”, please note it costs seven times more for storage and does not offer the same durability and availability, making it not suitable for long-term or general purpose storage.
My reaction: nice 🙂
See more: announcement post
OpenSearch Serverless: vector engine
The vector engine for OpenSearch Serverless, meant as a database for ML/AI models, is now generally available. Interestingly, the OpenSearch and OpenSearch Serverless diverge more and more, with the Serverless version getting unique new features.
My opinion: I saw at least five new or adapted vector databases this year, so this one does not surprise me. And all would be good if not for the OpenSearch Serverless costs – starting with $700/month. However, in the announcement post, they write about the possibility of using no active replicas and 0.5 computing units for development, which would land it around $170/month? I’m not entirely sure since there is no mention of it on the pricing page.
My reaction: not my area, hard to say 😶
See more: announcement post
Integrated Application Test Kit
The Integrated Application Test Kit, or IATK, is a new library helping to run tests for serverless applications in the cloud. It has a few useful features, like resolving resource physical IDs from the CloudFormation stack or waiting for asynchronous EventBridge events.
The library is available in public preview and, for now, only in Python.
My opinion: I’m looking forward to library development, both in terms of new features and supported platforms (Node.js in particular). The current capabilities are limited, and a lot will depend on the development team’s direction. But in a good scenario, it can become the base for running integration tests, replacing the helpers I currently write on my own.
Reaction: curious 🤔
See more: announcement post
Not Serverless (but still interesting)
Aurora: Limitless preview
Scaling SQL databases is hard. Scaling SQL databases for writes is especially hard. And this is the problem the new Aurora Limitless Database tackles.
The Limitless Database uses data sharding to spread the load on multiple instances and transaction routers to manage writes and reads to/from shards. Unlike the read replicas, this horizontal scaling works for both read and write operations. And thanks to the routers, the sharding is transparent for the client.
The Aurora Limitless is now in a limited preview. You can sign up for access.
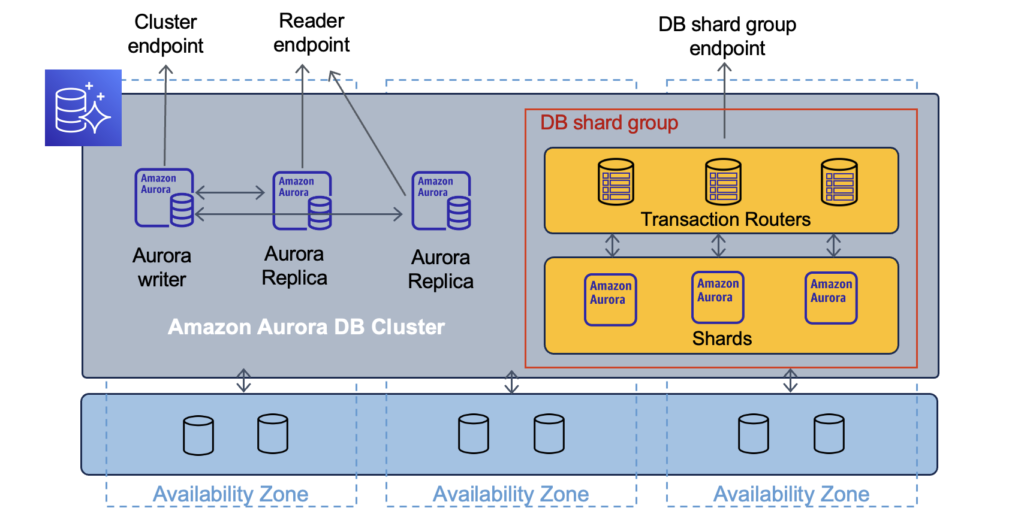
My opinion: While data sharding is not new, having it as a managed AWS service removes a lot of complexity for extremely high-traffic applications requiring SQL.
My reaction: academically interested 🤓
See more: announcement post
OpenSearch: direct S3 queries
You can now connect OpenSearch to S3 and make queries on the data in the buckets. Similarly to Athena, it uses the Glue Data Catalog to represent your S3 data as tables. You can select one of the three indexing strategies, from ingesting only metadata to ingesting all the data from S3 to OpenSearch, which translates to query performance.
Indexing and making queries consume compute units, which is an additional cost to your OpenSearch cluster. While no compute units are consumed while “no queries or indexing activities are active”, I’m not sure how that relates to keeping the S3 index up to date and whether it’s 24/7 activity.
My opinion: Yes, it looks like Athena with extra steps. However, I see the benefit of making queries through a single engine in a uniform way. Moreover, indexing data in OpenSearch should significantly outperform Athena.
My reaction: interested 🧐
See more: announcement post
AWS SDK for Rust and Kotlin
The Rust and Kotlin AWS SDKs become generally available.
My opinion: I’m not planning to use any of those two languages in the foreseeable future. But I know the community highly anticipated at least the Rust SDK, so I’m happy for the folks using it.
My reaction: nice 🙂
See more: Rust AWS SDK announcement post, Kotlin AWS SDK announcement post
Cost Optimization Hub
The Billing and Cost Management pages are now merged into one. I never understood why they were separate, and I had to jump through the links in the first place.
In this new management page, there is now a Cost Optimization Hub. It aggregates optimization suggestions from over ten different services.
Using Cost Optimization Hub is free, but you must opt-in to enable it. For best results, you must also opt-in to Compute Optimizer.
My opinion: While it’s an improvement, I don’t understand why we now have separate Cost Optimization Hub and Compute Optimizer, especially since the first takes the data from the latter.
My reaction: confused 🤨
See more: announcement
myApplications
The Console Home page now has myApplications view, where you can create applications and get a dashboard with costs, alarms, security findings, and other widgets just for selected resource groups.
You add resources to the applications by tagging them with a special awsApplication tag. You can choose resources manually or select a CloudFormation stack, and all its resources will be tagged for you, which is nice.
But even better is to add the tag to all resources in your stack(s), for example, with the CDK Tags aspect.
There is also an AWS::ServiceCatalogAppRegistry::ResourceAssociation CloudFormation resource suggested by the myApplications page that you can add to the stack.
While I understand that it should associate your stack with the application, it does not work, and myApplications shows that you must add tags anyway.
My opinion: I know the lack of logical “here is your application and all its resources” groups in AWS is somewhat intimidating for beginners. But I doubt this is helpful for those new users – it took me about 15 minutes to fully understand how it works… Besides, if you follow the basics of best practices to work with AWS, you have a single application deployed per account, so it’s not needed. And I don’t understand why this is a separate thing to Resource Groups instead of an integral part of it…
My reaction: meh 😒
See more: announcement post
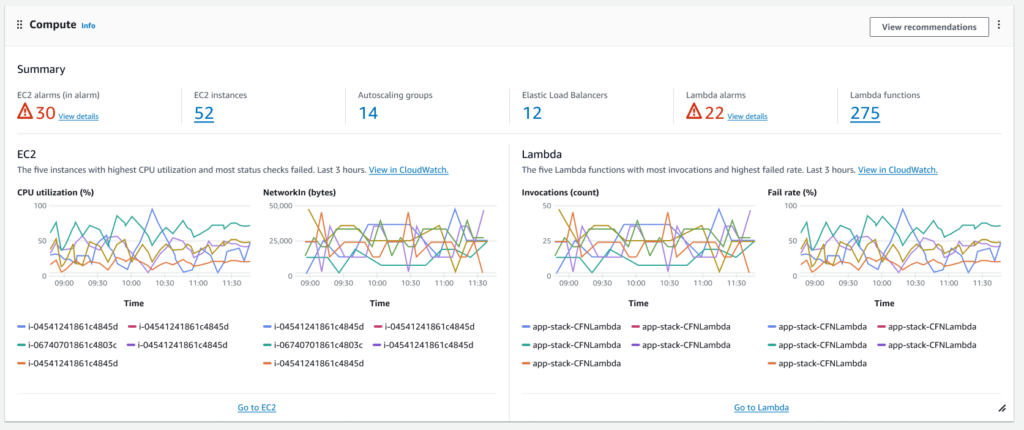
CloudWatch: Application Signals
In short, it’s automatic instrumentation and monitoring of EKS Clusters. You can also use it for non-EKS applications by running the CloudWatch agent on your ECS Cluster or EC2 instance yourself. Notably, for now, the instrumentation works only for Java applications.
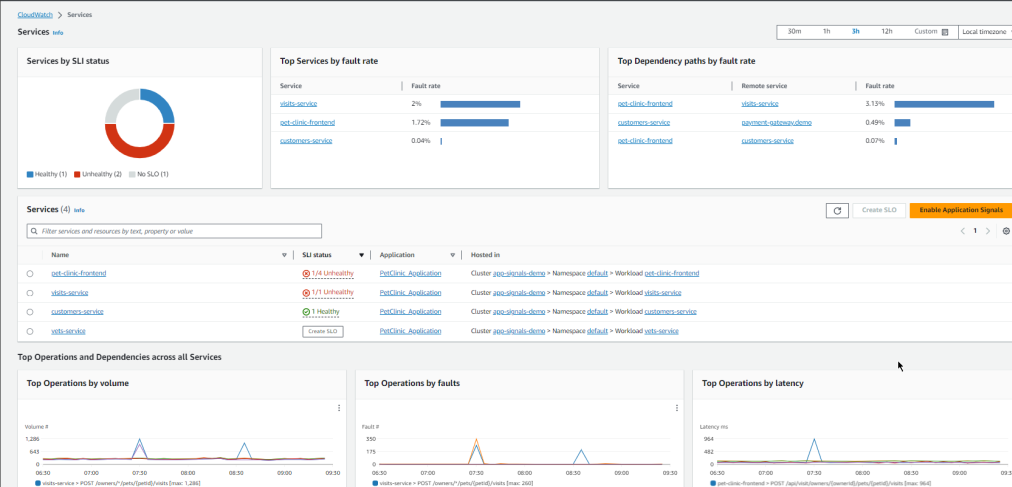
Another introduced capability of Application Signals is Service Level Objective (SLO) monitoring. You can monitor one of the discovered services or a CloudWatch Metric and set the target objective. Then, you can tell your customers about the 99.9% uptime of your application based on the actual data.
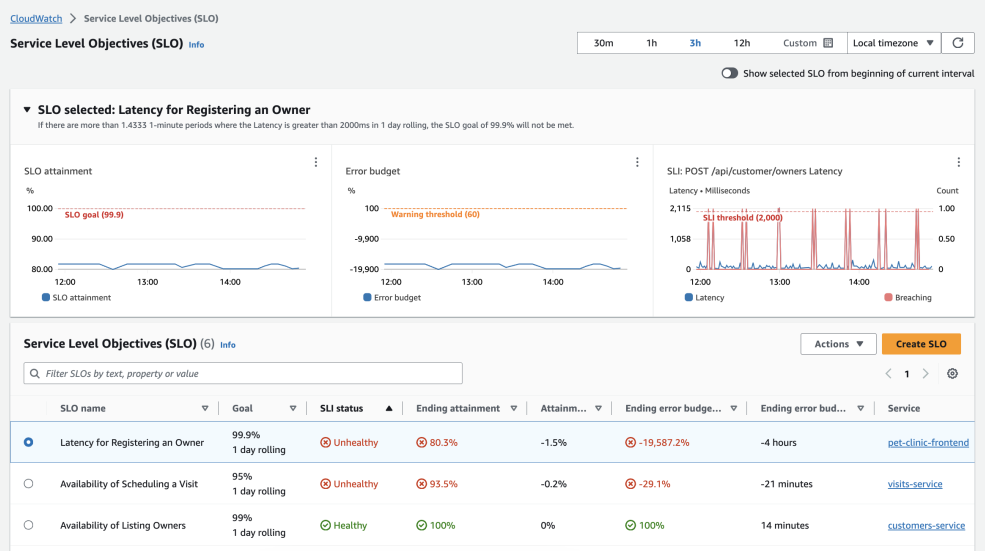
My opinion: I’ve been lucky enough never to use Kubernetes, and I do not intend to. But I hope my less fortunate colleagues will find Application Signals useful.
My reaction: nice 🙂
See more: announcement post
Q: the AWS AI
I’ve left the “best” for the end. There are multiple levels to unpack here, so bear with me.
Not surprisingly, the “AI” continued to pop up everywhere during the re:Invent, for better or worse. Undoubtedly, the biggest announcement in this area was Amazon Q, the AWS response to Large Language Models (LLM) taking over the world.
But what is Q? Well, it’s one thing in four forms.
Form 1: generative AI service
The Amazon Q service lets you create customized LLM working in a ChatGPT style, trained on the materials you provide. Those may be, for example, your company knowledge database enhancing Q with domain-specific facts. You can use a few configuration tweaks to tune and improve responses, like restricting irrelevant topics or defining the context for the answers.
A side note: extra points for the short and simple service name. Totally unrelated: do you know how many letters you must write in the AWS Console search bar to get results to find the service?
Form 2: AWS AI assistant
Without a doubt, you will notice the new popups in the AWS docs and the Console itself with an Amazon Q chat. You can ask it about AWS services and features and hope for the correct answer. It’s the Q service in practice, trained on AWS documentation, showing the service’s capabilities. It’s an excellent example of AWS dogfooding.
However, it shows not only the good but also the bad sides of Amazon Q. Like every LLM, it’s prone to hallucinations, as shown on many screenshots circulating on Twitter. See this thread from Corey Quinn as an example.

It also does not know about resources in your account and does not make any operations. Thus, asking it about the total number of your Lambda functions will only give you a CLI command to check it yourself.
It’s also integrated with CodeWhisperer, so you can chat with it without leaving your IDE.
Form 3: troubleshooting helper
There are new troubleshooting tools integrated into the AWS Console that use Q. Right now, it can help find the failed Lambda invocation error root cause or debug VPC connectivity issues.

Form 4: context-aware query generator
In Redshift, you can now write your question in a natural language and get SQL matching your tables in a response. That’s actually pretty awesome. I hope similar functionalities will also land in other services.
It’s still the preview
Everyone expects the best from AWS, but Amazon Q and all the capabilities it powers are still in the preview, so some hiccups are understandable. I’m sure AWS will fine-tune it to reduce hallucinations and give better answers.
My opinion: Finding the appropriate documentation page in Google takes me less time than waiting for the chatbot’s answer. But I’ll give it a go. For now, I like that Amazon Q’s answers include the links to the documentation sources.
My reaction: mixed feelings 😵💫
See more: announcement post
Conclusion
Wow, that turned out long.
Recordings from re:Invent are available on YouTube: keynotes, hundreds of presentations.
Please let me know in the comments if there is anything you liked the most from the announcements!

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.