Here I show three ways to create Amazon Athena tables. More importantly, I show when to use which one (and when don’t) depending on the case, with comparison and tips, and a sample data flow architecture implementation. Also, I have a short rant over redundant AWS Glue features. All in a single article. Enjoy.
Amazon Athena and data
Amazon Athena is a serverless AWS service to run SQL queries on files stored in S3 buckets. It’s used for Online Analytical Processing (OLAP) when you have Big Data ALotOfData™ and want to get some information from it. It’s also great for scalable Extract, Transform, Load (ETL) processes.
To run a query you don’t load anything from S3 to Athena. The only things you need are table definitions representing your files’ structure and schema.
Data Catalogs, Databases and Tables
Before we begin, we need to make clear what the table metadata is exactly and where we will keep it.
The metadata is organized into a three-level hierarchy:
- Data Catalog
- Database
- Table
Data Catalog is a place where you keep all the metadata. There are two options here. The default one is to use the AWS Glue Data Catalog. As the name suggests, it’s a part of the AWS Glue service. The alternative is to use an existing Apache Hive metastore if we already have one.
Then we have Databases. Here they are just a logical structure containing Tables. It makes sense to create at least a separate Database per (micro)service and environment.
Tables are what interests us most here. They contain all metadata Athena needs to know to access the data, including:
- location in S3
- files format
- files structure
- schema – column names and data types
We create a separate table for each dataset. Let’s say we have a transaction log and product data stored in S3. They may be in one common bucket or two separate ones. They may exist as multiple files – for example, a single transactions list file for each day. Regardless, they are still two datasets, and we will create two tables for them.
Contrary to SQL databases, here tables do not contain actual data. Data is always in files in S3 buckets. We only need a description of the data.
Knowing all this, let’s look at how we can ingest data. Next, we will see how does it affect creating and managing tables.
Sample data flow
Let’s take this simple data flow:
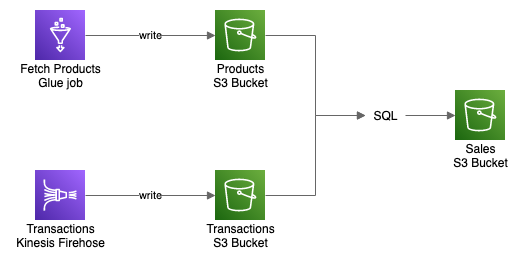
Firstly we have an AWS Glue job that ingests the Product data into the S3 bucket. It can be some job running every hour to fetch newly available products from an external source, process them with pandas or Spark, and save them to the bucket.
Secondly, there is a Kinesis Firehose saving Transaction data to another bucket. That may be a real-time stream from Kinesis Stream, which Firehose is batching and saving as reasonably-sized output files.
And then we want to process both those datasets to create a Sales summary. Our processing will be simple, just the transactions grouped by products and counted. More complex solutions could clean, aggregate, and optimize the data for further processing or usage depending on the business needs.
We could do that last part in a variety of technologies, including previously mentioned pandas and Spark on AWS Glue. But there are still quite a few things to work out with Glue jobs, even if it’s serverless – determine capacity to allocate, handle data load and save, write optimized code. What if we can do this a lot easier, using a language that knows every data scientist, data engineer, and developer (or at least I hope so)? And I don’t mean Python, but SQL.
Creating Athena tables
To make SQL queries on our datasets, firstly we need to create a table for each of them.
There are three main ways to create a new table for Athena:
- using AWS Glue Crawler
- defining the schema manually
- through SQL DDL queries
We will apply all of them in our data flow. The effect will be the following architecture:
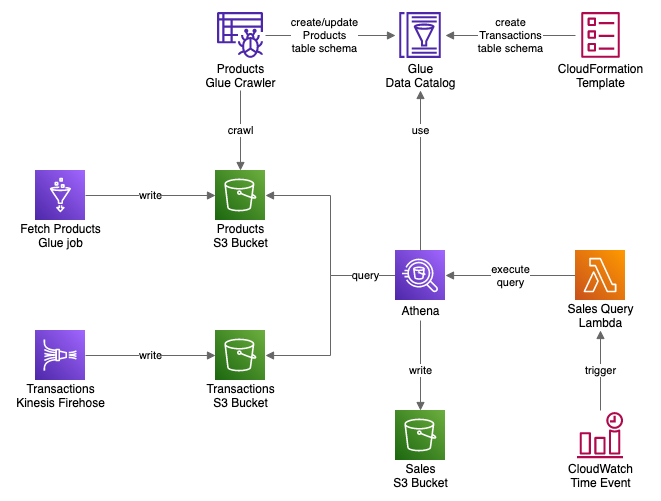
I put the whole solution as a Serverless Framework project on GitHub. Input data in Glue job and Kinesis Firehose is mocked and randomly generated every minute. AWS will charge you for the resource usage, so remember to tear down the stack when you no longer need it.
Let’s start with creating a Database in Glue Data Catalog. Next, we will create a table in a different way for each dataset.
resources:
Resources:
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: myathenatables
Creating table with AWS Glue crawler
New files are ingested into the Products bucket periodically with a Glue job. Here is a definition of the job and a schedule to run it every minute. You can find the full job script in the repository.
resources:
Resources:
# ...
FetchProductsGlueJob:
Type: AWS::Glue::Job
Properties:
Name: fetchProducts
Command:
Name: pythonshell
PythonVersion: 3
ScriptLocation: !Sub s3://${ProductsBucket}/fetch_products.py
DefaultArguments:
'--target-bucket-name': !Ref ProductsBucket
GlueVersion: '1.0'
MaxCapacity: 0.0625
Timeout: 5
ExecutionProperty:
MaxConcurrentRuns: 5
Role: !Ref FetchProductsJobRole
FetchProductsJobTrigger:
Type: AWS::Glue::Trigger
Properties:
Name: fetchProductsJob
Type: SCHEDULED
StartOnCreation: true
Actions:
- JobName: !Ref FetchProductsGlueJob
Schedule: cron(* * * * ? *)
ProductsBucket:
Type: AWS::S3::Bucket
We save files under the path corresponding to the creation time. Those paths will create partitions for our table, so we can efficiently search and filter by them.
In such a case, it makes sense to check what new files were created every time with a Glue crawler. The crawler’s job is to go to the S3 bucket and discover the data schema, so we don’t have to define it manually. It will look at the files and do its best to determine columns and data types.
The crawler will create a new table in the Data Catalog the first time it will run, and then update it if needed in consequent executions. Why we may need such an update? New data may contain more columns (if our job code or data source changed). More often, if our dataset is partitioned, the crawler will discover new partitions.
There are several ways to trigger the crawler:
- manually, from Console, SDK, or CLI
- with a CRON-based time event
- after another crawler or job finished
- with Glue Workflows
What is missing on this list is, of course, native integration with AWS Step Functions. At the moment there is only one integration for Glue – to run jobs. If we want, we can use a custom Lambda function to trigger the Crawler.
A truly interesting topic are Glue Workflows. They are basically a very limited copy of Step Functions. Limited both in the services they support (which is only Glue jobs and crawlers) and in capabilities. It looks like there is some ongoing competition in AWS between the Glue and SageMaker teams on who will put more tools in their service (SageMaker wins so far). And this is a useless byproduct of it. In short, prefer Step Functions for orchestration. Rant over.
Here, to update our table metadata every time we have new data in the bucket, we will set up a trigger to start the Crawler after each successful data ingest job.
resources:
Resources:
# ...
ProductsCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: products
DatabaseName: !Ref GlueDatabase
Role: !GetAtt ProductsCrawlerRole.Arn
Targets:
S3Targets:
- Path: !Sub s3://${ProductsBucket}/products
Configuration: >
{
"Version": 1.0,
"Grouping": {
"TableGroupingPolicy": "CombineCompatibleSchemas"
}
}
FetchProductsCrawlerTrigger:
Type: AWS::Glue::Trigger
Properties:
Name: productsCrawler
Type: CONDITIONAL
StartOnCreation: true
Actions:
- CrawlerName: !Ref ProductsCrawler
Predicate:
Conditions:
- JobName: !Ref FetchProductsGlueJob
LogicalOperator: EQUALS
State: SUCCEEDED
And that’s all. After the first job finishes, the crawler will run, and we will see our new table available in Athena shortly after.
Creating table manually
The Transactions dataset is an output from a continuous stream. We will partition it as well – Firehose supports partitioning by datetime values. For demo purposes, we will send few events directly to the Firehose from a Lambda function running every minute.
resources:
Resources:
# ...
TransactionsFirehose:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamType: DirectPut
S3DestinationConfiguration:
BucketARN: !GetAtt TransactionsBucket.Arn
BufferingHints:
IntervalInSeconds: 60
CompressionFormat: UNCOMPRESSED
Prefix: 'transactions/!{timestamp:yyyy/MM/dd/HH/mm}/'
ErrorOutputPrefix: 'transactions-errors/!{firehose:error-output-type}/!{timestamp:yyyy/MM/dd/HH/mm}/'
RoleARN: !GetAtt TransactionsFirehoseRole.Arn
TransactionsBucket:
Type: AWS::S3::Bucket
Using a Glue crawler here would not be the best solution. New files can land every few seconds and we may want to access them instantly. We don’t want to wait for a scheduled crawler to run.
For this dataset, we will create a table and define its schema manually. And by “manually” I mean using CloudFormation, not clicking through the “add table wizard” on the web Console.
But what about the partitions? How will Athena know what partitions exist? To solve it we will use Partition Projection. In short, we set upfront a range of possible values for every partition.
resources:
Resources:
# ...
TransactionsTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref GlueDatabase
TableInput:
Name: transactions
TableType: EXTERNAL_TABLE
Parameters:
projection.enabled: true
projection.datetime.type: date
projection.datetime.range: '2021/01/01/00/00,NOW'
projection.datetime.format: 'yyyy/MM/dd/HH/mm'
projection.datetime.interval: 1
projection.datetime.interval.unit: MINUTES
storage.location.template: !Join [ '', [ 's3://', !Ref TransactionsBucket, '/transactions/$', '{datetime}' ] ]
PartitionKeys:
- Name: datetime
Type: string
StorageDescriptor:
Location: !Sub s3://${TransactionsBucket}/transactions/
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SerdeInfo:
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
Columns:
- Name: id
Type: varchar(64)
- Name: product_id
Type: varchar(64)
- Name: created_at
Type: timestamp
As you see, here we manually define the data format and all columns with their types.
Creating table through SQL query
With tables created for Products and Transactions, we can execute SQL queries on them with Athena.
Athena supports not only SELECT queries, but also CREATE TABLE, CREATE TABLE AS SELECT (CTAS), and INSERT. We can use them to create the Sales table and then ingest new data to it.
There are two things to solve here.
Firstly, we need to run a CREATE TABLE query only for the first time, and then use INSERT queries on subsequent runs.
Secondly, we need to schedule the query to run periodically.
Let’s start with the second point. Athena does not have a built-in query scheduler, but there’s no problem on AWS that we can’t solve with a Lambda function. We can create a CloudWatch time-based event to trigger Lambda that will run the query.
Now, since we know that we will use Lambda to execute the Athena query, we can also use it to decide what query should we run.
It’s pretty simple – if the table does not exist, run CREATE TABLE AS SELECT. Otherwise, run INSERT.
functions:
salesQueryRunner:
handler: src/sales/index.handler
events:
- schedule: rate(1 minute)
environment:
BUCKET_NAME: !Ref SalesBucket
DATABASE_NAME: !Ref GlueDatabase
resources:
Resources:
# ...
SalesBucket:
Type: AWS::S3::Bucket
const {Athena} = require('@aws-sdk/client-athena');
const {Glue} = require('@aws-sdk/client-glue');
const {DateTime} = require('luxon');
const athena = new Athena({apiVersion: '2017-05-18'});
const glue = new Glue({apiVersion: '2017-03-31'});
const bucketName = process.env.BUCKET_NAME;
const databaseName = process.env.DATABASE_NAME;
const tableName = 'sales';
exports.handler = async () => {
// query data from 3 minutes ago so both Firehose and Glue crawler
// for given minute already finished
const datetime = DateTime.utc().minus({minutes: 3});
const tableExists = await tableExists(databaseName, tableName);
const createOrInsert = tableExists ?
buildInsertInto(databaseName, tableName) :
buildCreateTable(databaseName, tableName, bucketName);
const query = `
${createOrInsert}
${buildQueryBody(databaseName, datetime)}
`;
await athena.startQueryExecution({
QueryString: query,
ResultConfiguration: {
OutputLocation: `s3://${bucketName}/queries/`
}
});
};
const tableExists = async (database, table) => {
try {
await glue.getTable({
DatabaseName: database,
Name: table,
});
return true;
} catch (e) {
if (e.name === 'EntityNotFoundException') {
return false;
} else {
throw e;
}
}
};
const buildInsertInto = (database, table) =>
`INSERT INTO "${database}"."${table}"`;
const buildCreateTable = (database, table, bucket) => `
CREATE TABLE "${database}"."${table}"
WITH (
external_location = 's3://${bucket}/${table}',
format = 'JSON'
) AS`;
const buildQueryBody = (database, dt) => `
SELECT
p.id AS product_id,
COUNT(t.id) AS count
FROM "${database}"."products" p
JOIN "${database}"."transactions" t ON p.id = t.product_id
WHERE
p.year = '${dt.toFormat('yyyy')}' AND p.month = '${dt.toFormat('MM')}' AND p.day = '${dt.toFormat('dd')}'
AND p.hour = '${dt.toFormat('HH')}' AND p.minute = '${dt.toFormat('mm')}'
AND t.datetime = '${dt.toFormat('yyyy/MM/dd/HH/mm')}'
GROUP BY p.id`;
There are two things worth noticing here. First, we do not maintain two separate queries for creating the table and inserting data. We only change the query beginning, and the content stays the same. That makes it less error-prone in case of future changes. And second, the column types are inferred from the query. We don’t need to declare them by hand.
Methods comparison
| Glue crawler | Manual (CF) | SQL CTAS | |
|---|---|---|---|
| Schema definition | Auto-detected | Declared | Inferred and/or declared |
| Auto schema update | Yes | No | No |
| Pricing (USD) | $0.44 per DPU-Hour, min.$0.073 per run | $0.00 | $5.00 per TB of data scanned1 |
| Control over table settings | Low | Full | Medium |
| Typical use case | Periodic ingest of new data partitions | Not-partitioned data or partitioned with Partition Projection | SQL-based ETL process and data transformation |
1To just create an empty table with schema only you can use WITH NO DATA (see CTAS reference). Such a query will not generate charges, as you do not scan any data.
As you can see, Glue crawler, while often being the easiest way to create tables, can be the most expensive one as well.
Final notes
A few explanations before you start copying and pasting code from the above solution.
Multiple tables can live in the same S3 bucket. I prefer to separate them, which makes services, resources, and access management simpler. And I never had trouble with AWS Support when requesting for bucket’s number quota increase.
JSON is not the best solution for the storage and querying of huge amounts of data. I used it here for simplicity and ease of debugging if you want to look inside the generated file. For real-world solutions, you should use Parquet or ORC format. Why? The files will be much smaller and allow Athena to read only the data it needs. That can save you a lot of time and money when executing queries. It’s further explained in this article about Athena performance tuning. If you haven’t read it yet – you should probably do it now.
Keeping SQL queries directly in the Lambda function code is not the greatest idea as well.
Again – I did it here for simplicity of the example.
There should be no problem with extracting them and reading from separate *.sql files. For variables, you can implement a simple template engine.
If you are working together with data scientists, they will appreciate it.
Running a Glue crawler every minute is also a terrible idea for most real solutions. It’s not only more costly than it should be but also it won’t finish under a minute on any bigger dataset.
For orchestration of more complex ETL processes with SQL, consider using Step Functions with Athena integration.
The example project repository:
I plan to write more about working with Amazon Athena. If you are interested, subscribe to the newsletter so you won’t miss it.
Questions, objectives, ideas, alternative solutions? Please comment below.

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.