After tabs vs. spaces, vi vs. emacs, let’s fight over this: which is better, Node.js or Python for AWS Lambda and serverless in general? I have my opinion on this, and the fact I prefer TypeScript over Python makes me only slightly biased.
AWS Lambda: Node.js and Python lead popularity
From six available native Lambda runtimes, Node.js and Python are unquestionable leaders in popularity.
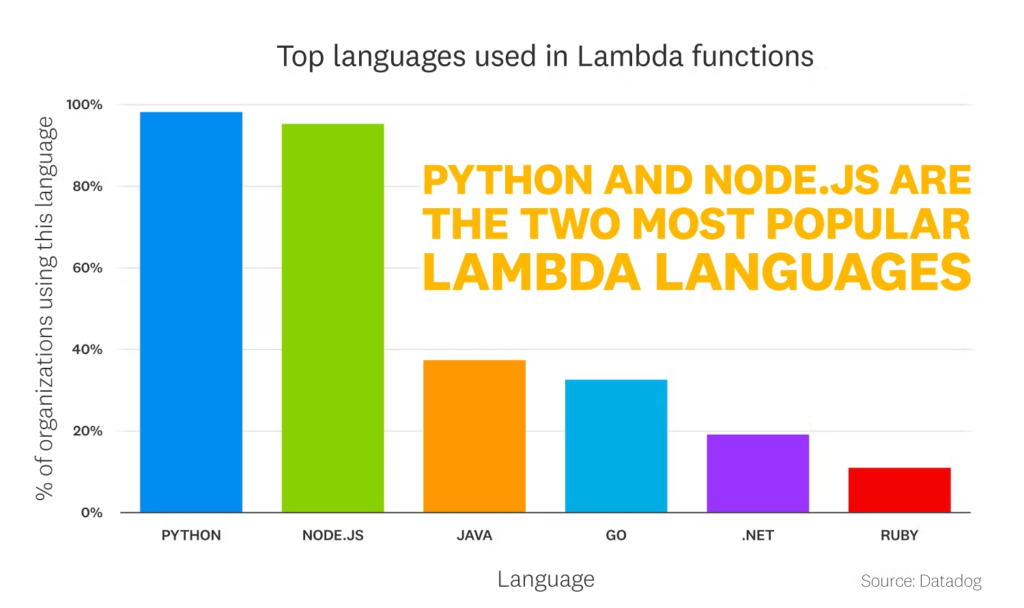
Node.js and Python are usually chosen for new Lambda functions, while the other runtimes are often (but not always) used when migrating legacy applications to serverless.
With Node.js, we must also remember that there are two camps here: pure JavaScript fans and strict TypeScript enjoyers. Yes, TypeScript is transpiled to JavaScript to run on Node.js. But it changes the discussion from “Node.js vs. Python” to “JavaScript vs. TypeScript vs. Python”.
When to ignore the rest of this post?
Before we jump into any comparison of those two runtimes, let’s make something clear.
Node.js and Python runtimes for AWS Lambda are similar. They have comparable cold start and runtime overhead. For both, there is a huge community with numerous open-source libraries. And both are similarly supported by AWS, with the availability of libraries like SDK, CDK, or long wait times for new runtimes (respectively: Node.js 18, Python 3.10).
So if you already have any reason to choose one over another – you have your answer for what’s best for you. Those reasons will most often be:
- Task specificity. Always choose the best tool for the job. For example, Python will be a better choice if you are doing Machine Learning in Lambda because there is a rich ecosystem of ML libraries in Python.
- Familiarity in the team. Suppose your whole team knows TypeScript inside out. In that case, unnecessary switching to Python will only result in a slowdown due to learning and a “Crappy Python”, a very common implementation of Python by beginners.
But if you are doing “standard stuff” in Lambda that you can easily implement in any language, and (part) of your team would need to learn the chosen language either way, let’s start the discussion: Node.js or Python?
Lambda runtime comparison criteria
This article could quickly become Python vs. JavaScript/TypeScript. But I’m interested in the serverless aspect, specifically the AWS Lambda. So let’s put aside and not compare:
- Language features and which is generally better (as we know, it’s TypeScript due to being strongly typed – did I mention I’m biased?),
- Runtime performance, as the differences are negligible and more depends on how you write the code than on the language you choose,
- AWS SDK, since they both have their own, each with slightly different features, pros and cons, but capable of doing everything needed.
Instead, we will focus on how well each technology supports building Lambda functions.
The winner is Node.js
Okay, there is no point in deceiving you with some comparison. In my opinion, Node.js wins. And I have arguments to back this up.
What are those arguments? There are three: smaller bundle size, easier and faster bundling, and better monorepo support for serverless projects.
Reason 1: Lambda bundle size
To deploy a Lambda function, you bundle your code and its dependencies (libraries you use) into a zip file and upload it to an S3 bucket. Well, usually, a tool you use for deployments does it, but the zip file is a fact anyway.
And there are two reasons to keep this bundle small:
- the 250 MB size limit (unzipped),
- cold starts duration.
The 250 MB Lambda size limit includes the function code and the layers, so packaging dependencies separately in the layers (as some do) is not a solution. If your bundle exceeds this size, you can’t deploy your function on AWS-provided Node.js or Python Lambda runtime. Instead, you must build it as a Docker image. Using a Docker image for your Lambda is feasible but adds additional overhead and complexity, removing security gains from having a fully managed environment. And also, Docker has ~3 times bigger cold starts than the native Node.js / Python runtime.
And about the cold starts… Generally, AWS Lambda cold starts are not as big of a problem as some think. But it’s worth noting that the bundle size affects the cold start time. So even though we usually shouldn’t worry about the cold starts so much, it’s nice to keep the bundle small if possible.
So why is Python worse than Node.js regarding bundle size? Isn’t Node.js known for the gigantic node_modules dependencies directories?
The answer is tree-shaking.
With Node.js, it’s common to use a bundler like esbuild, webpack, or Rollup to, well, bundle your sources and libraries into a minified package. And those bundlers do a neat trick: they omit any unused code. So even if you add a huge library as a dependency, only the parts your code needs to work will get into the final bundle. Additionally, bundlers minify the code, further reducing the final zip size.
However, tree-shaking is not possible with Python, in which code imports are far more dynamic and there is no way for the bundler to detect dead code statically.
The best example is… boto3, the AWS SDK for Python:
import boto3
s3 = boto3.client('s3')
How could any bundler know which parts of the boto3 library you need? It does not, so you end up with the whole 75 MB of the SDK.
Sure, you can omit the AWS SDK from the bundle, as it’s available in the Lambda runtime, but the rule stays the same for other Python packages.
You need pandas? Say hello to 164 MB of dependencies because pandas come with its best friend, numpy. Together they exceed half of the maximum Lambda package size.
And it doesn’t matter that you want to use only a fraction of pandas capabilities.
Moreover, part of these libraries are tests and configuration files that you definitely do not need for your code to work, but they come in a package and there is no uniform way to get rid of them while bundling your Python Lambda.
| Node.js | Python |
|---|---|
| 1 | 0 |
Reason 2: Ease of bundling Lambda functions
In the previous section, we touched on the problem with Python libraries. But that’s not the end because dependency management in Python is inherently broken (but it may get better, yay!).
In short: there is no unified way to access Python dependencies.
Among the three most popular dependency managers (pip, Poetry, and pipenv), each installs dependencies in different, not standardized locations. Then they rely on you to activate the proper virtual environment to access those dependencies. Additionally, since each uses a distinct format for keeping track of dependencies, separating the packages needed for production from the development ones is also not uniform.
Because of that, the only reliable way to bundle the Lambda function with its production dependencies is to install dependencies again in an isolated environment – a Docker container. That’s how you build Python Lambdas in both CDK and Serverless Framework.
But building Lambda functions in Docker containers has some drawbacks:
- You need Docker – maybe not a big problem, but always an additional element in the toolchain,
- During the build, your dependencies will be fetched from the internet again, even if you already installed them locally during the development,
- Furthermore, if you have two Lambda functions with (partially) overlapping dependencies, those dependencies will be fetched twice, independently, from the internet,
- And each time you modify the dependencies, all of them will be fetched from the internet again.
Internet is cheap and fast, but does it justify downloading the same libraries over and over again? And it takes time – even if only extra 30 seconds or 1 minute, it’s noticeable.
Meanwhile, with Node.js, you install dependencies once, and every build tool knows how to access them. Even if multiple Lambdas use the same dependencies, they are still downloaded once. And you don’t need Docker to bundle them.
| Node.js | Python |
|---|---|
| 2 | 0 |
Reason 3: Monorepo tooling support
Serverless projects are inherently tied to monorepos. They contain multiple Lambda functions that usually differ in dependencies, and including all needed dependencies in every Lambda is a no-no for the bundle-size reasons described before.
And Node.js environment has the biggest tooling ecosystem around monorepos. Probably even too big, if I’m honest.
All popular Node.js dependency managers (npm, yarn, and pnpm) support monorepos in the form of workspaces. You can install common tooling (like test runners and linters) at the root project level and specific dependencies for each sub-project (Lambda functions). Then, with a single command, you can execute actions across all sub-projects: install dependencies, run unit tests, etc. Meanwhile, none of the most popular Python dependency managers supports managing anything more than one package.
But if the workspace support offered by dependency managers is not enough, Node.js has several specialized monorepo management tools. Especially Nx and Turborepo are often mentioned in the context of serverless applications. On the Python side – I found Pants which seems similar in capabilities, so it’s something at least? But it’s hard to find examples of using it with serverless apart from their own docs.
And yes, you can use one of Node.js monorepo tools and still write your code in Python. But then you mix both worlds, adding development environment requirements, setup steps, and configs in different languages. That’s an additional complexity that is probably unjustified in most projects.
| Node.js | Python |
|---|---|
| 3 | 0 |
| 🥇 | 🥈 |
Please do correct me
I tried to stay objective. Really.
But in the end, I will always choose Node.js over Python for serverless development if there are no particular reasons (task specificity or familiarity in the team) to use Python. Node.js Lambda functions are smaller thanks to the tree-shaking, which helps to avoid running into the 250 MB bundle limit. They are faster to build and deploy because no Docker container is needed to reliable bundle them with dependencies. And finally, the Node.js ecosystem provides better monorepo support, which is typical for serverless projects.
However, I live in my bubble. If you disagree and have solutions to my pains with Python for serverless development – please let me know! I use Python when it makes sense – especially for Machine Learning or data-heavy projects. I would love to improve my experience with it.

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.