- Simple Kinesis trigger
- A General Pitfall: not specifying trigger parameters
- Pitfall #1: small batch size
- Pitfall #2: no error handling
- Pitfall #3: wrong starting position
- Pitfall #4: insufficient parallelization
- Pitfall #5: unnoticed processing lag
- Pitfall #6: lack of stream monitoring
- Conclusion and Bonus
The simplicity of setting up a Kinesis trigger for a Lambda function may be deceptive. There are pitfalls that can cause problems we will spot only later, in the production environment. I learned about some of them the hard way, so let’s say I speak from the experience.
➡️ This article was originally posted on the Dashbird blog
I wrote about the differences between various AWS messaging services and how to choose between them. One of the options is the Kinesis Data Stream. It’s a powerful service, so let’s dig into it today.
Kinesis Data Streams are the solution for real-time streaming and analytics at scale. As we learned in November 2020, AWS themselves use it internally to keep, well, AWS working.
Kinesis works very well with AWS Lambda. Creating a function that will process incoming records is easy, especially if we leverage the Serverless Framework or SAM to deploy required resources. But simply setting up the Lambda to read from the Kinesis is rarely enough.
Simple Kinesis trigger
Let’s start with a Kinesis stream and a Lambda function that handles incoming records. I will use the Serverless Framework here, but we can achieve the same with SAM or raw CloudFormation.
functions:
consumer:
name: ${self:custom.baseName}-consumer
handler: src/index.handler
events:
- stream:
type: kinesis
arn:
Fn::GetAtt: [ KinesisStream, Arn ]
resources:
Resources:
KinesisStream:
Type: AWS::Kinesis::Stream
Properties:
Name: ${self:custom.baseName}
RetentionPeriodHours: 24
ShardCount: 2
The stream we created will keep records for 24 hours and will consist of two shards. Each shard provides a defined max throughput. Records from a single shard are delivered in order.
Our Lambda function will be just as simple:
import {KinesisStreamHandler} from 'aws-lambda/trigger/kinesis-stream';
import {logger} from './logger';
export const handler: KinesisStreamHandler = async (event) => {
logger.info('Records count', {count: event.Records.length});
event.Records.forEach((record, index) => {
const data = JSON.parse(Buffer.from(record.kinesis.data, 'base64').toString('utf-8'));
logger.info('Record', {
index,
eventId: record.eventID,
eventName: record.eventName,
partitionKey: record.kinesis.partitionKey,
sequenceNumber: record.kinesis.sequenceNumber,
approximateArrivalTimestamp: record.kinesis.approximateArrivalTimestamp,
data: record.kinesis.data,
parsedData: data,
});
});
};
A General Pitfall: not specifying trigger parameters
With the Lambda trigger defined as above, we rely on the Serverless Framework to set its parameters.
Some default values generated by the SF are different from CloudFormation defaults for the Lambda trigger (AWS::Lambda::EventSourceMapping resource). That could be a sufficient argument to define them explicitly – there is a smaller chance that someone will assume their values incorrectly by looking at the wrong documentation.
However, what’s even more important is the fact that the default values will rarely suit us in practice.
Since this is A General Pitfall, let’s break it into smaller ones by looking at what we can do wrong (and how to fix it!) with different parameters.
Pitfall #1: small batch size
If we start sending messages to the stream every second and look into the CloudWatch Logs Insights to check how many records are processed by the Lambda at once, we will see something like this:
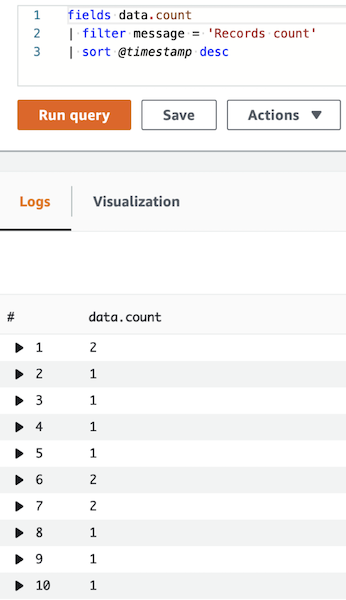
Lambda took ten records, processed them, and took the next batch. Then repeated this until there were no more items in the stream.
Two sub-optimal things are going on here. Firstly, since we process messages as fast as they are incoming, our Lambda is invoked for almost every record separately. Secondly, when items accumulate in the stream, Lambda takes no more than ten at a time.
Why is it bad?
With only one record processed each time, we have more Lambda invocations to pay for. But that’s not all. We probably would like to do something with that record. Analyze, filter, and send to some API endpoint, database, etc. Those operations can usually take a batch of items – for example, we can add multiple items to the database with a single query. Processing and sending 10 or 100 records in a batch is usually much faster than doing it 10 or 100 times separately.
On top of that, we generate a load on the target service with each call. That increases its resource usage and/or costs. Business requirements often say “real-time processing”, but in reality, often a delay of 3, 5, or 15 seconds does not make any difference.
On the other hand, if we have a backlog of items to process, we take only 10. Is it optimal? Wouldn’t it be better (faster and cheaper) to process 100 at once, or, if we speak about it, 1000? Of course, the answer to this question will depend on what we actually do, our function logic, and the external calls we make. But we need to think about it and choose some value consciously.
How can we fix it?
With two parameters: batchSize and batchWindow.
batchSize sets the maximum number of records processed by the Lambda function at once.
batchWindow sets the maximum number of seconds to wait and accumulate records before triggering the Lambda.
Here we will set those parameters as follows:
functions:
consumer:
name: ${self:custom.baseName}-consumer
handler: src/index.handler
events:
- stream:
type: kinesis
arn:
Fn::GetAtt: [ KinesisStream, Arn ]
batchSize: 100
batchWindow: 5
What does it mean?
Lambda will trigger when there are 100 records in a stream shard, after 5 seconds, or after accumulating 6 MB of payload size (built-in limit), whatever will happen first.
Again, choosing those values depends on the business requirements. Not choosing them is rarely a valid option.
Pitfall #2: no error handling
Our Lambda is now processing a hundred records in each invocation. Everything runs smoothly until one malformed message comes in and our function throws an error.
If we worked with SQS before and expect the processing to be retried three times until the record is rejected, we will have a very unpleasant surprise. By default, Lambda will try to process the batch 10,000 times, the maximum possible number of retries. Moreover, it will not process further records until the problem is resolved. This is due to the Kinesis guarantee of in-order processing.
Of course, we may want to repeat the execution 10,000 times. Maybe the problem lies not in the data but in an external system we call. But more often, we want to skip the problematic message and continue with the next ones, preventing our systems from hanging with old data.
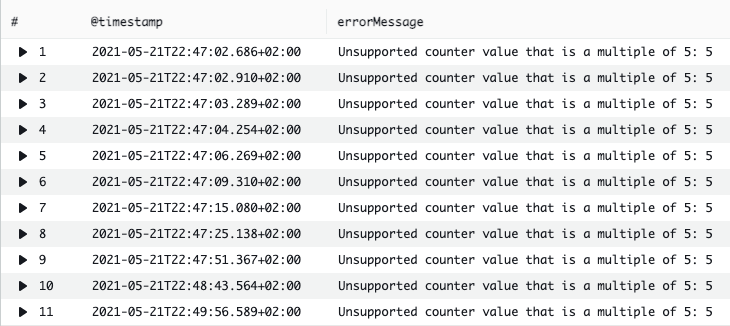
There are three parameters worth using for this case.
We will start with reducing the number of retries. To do so, we will set the maximumRetryAttempts.
While we can get notified about failures from the Lambda metrics, it’s generally a good idea to send info about unprocessed records to a Dead Letter Queue. This way, when we find and fix the faulty Lambda logic causing the problem, we can re-ingest dropped records.
Our DLQ can be an SQS or SNS that we reference under destinations.onFailure.
Here a clarification is needed: records themself are not sent to DLQ, only information about them. Each message will contain details about the failed batch position in the stream. So having it, we can later get records directly from the Kinesis as long as they don’t reach the retention period. Here is an example of such a message:
{
"requestContext": {
"requestId": "0c89d503-84bc-4c0f-8c8e-dba9a1b6c12a",
"functionArn": "arn:aws:lambda:eu-west-1:111111111111:function:blog-dev-kinesisPitfalls-consumer",
"condition": "RetryAttemptsExhausted",
"approximateInvokeCount": 6
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"version": "1.0",
"timestamp": "2021-05-18T20:55:25.098Z",
"KinesisBatchInfo": {
"shardId": "shardId-000000000000",
"startSequenceNumber": "49618380451877169115088686798050543476173874386899566594",
"endSequenceNumber": "49618380451877169115088686798066259511828865528243421186",
"approximateArrivalOfFirstRecord": "2021-05-18T20:23:08.319Z",
"approximateArrivalOfLastRecord": "2021-05-18T20:23:22.180Z",
"batchSize": 8,
"streamArn": "arn:aws:kinesis:eu-west-1:111111111111:stream/blog-dev-kinesisPitfalls"
}
}
Looking closely at this message, we will see that rejected was not only a single faulty record, but the whole batch of eight. If only a single record is making problems, we may still want to process others, not throw them out because of them being in the wrong company.
For that, the solution is a bisectBatchOnFunctionError option.
When set to true, each time the Lambda execution will fail, the batch will be split in two and retried separately. Depending on the batch size and number of retries, we may eventually isolate the single malformed record.
After discarding it, we can successfully process all others.
functions:
consumer:
name: ${self:custom.baseName}-consumer
handler: src/index.handler
events:
- stream:
type: kinesis
arn:
Fn::GetAtt: [ KinesisStream, Arn ]
batchSize: 100
batchWindow: 5
maximumRetryAttempts: 5
bisectBatchOnFunctionError: true
destinations:
onFailure:
type: sqs
arn:
Fn::GetAtt: [ RecordsDLQ, Arn ]
resources:
Resources:
KinesisStream:
Type: AWS::Kinesis::Stream
Properties:
Name: ${self:custom.baseName}
RetentionPeriodHours: 24
ShardCount: 2
RecordsDLQ:
Type: AWS::SQS::Queue
One thing worth noting is that retrying batches will cause some records to be processed multiple times. If the function logic is not idempotent or we don’t want to waste execution time on repeating successful actions, we can mitigate this problem using custom checkpoints.
Pitfall #3: wrong starting position
This is a problem we will usually face only when creating a new Kinesis trigger. But this moment can be during disaster recovery (as it was in my case), so it is better to prepare in advance.
Contrary to SQS, messages in Kinesis are not removed after being read by the client. Instead, each client keeps track of the last record it read. Lambda, of course, does it for us.
When we deploy a new Lambda function with a Kinesis as a trigger, it will start by reading all the existing records from the stream by default. Depending on the configured stream retention period, that can mean all messages from even the last 365 days.
No need to say it may not be what we aim to do. It can take long hours before we process all the old data and catch up with the current records. Not to mention a bill that it can cause.
For those reasons, if we want to process only the new messages incoming from the moment we deploy our function, we need to set the startingPosition explicitly.
The default value is TRIM_HORIZON – to start from the oldest record available.
To start from the latest record at the moment of function deployment, we change it to LATEST.
functions:
consumer:
name: ${self:custom.baseName}-consumer
handler: src/index.handler
events:
- stream:
type: kinesis
arn:
Fn::GetAtt: [ KinesisStream, Arn ]
startingPosition: LATEST
batchSize: 100
batchWindow: 5
maximumRetryAttempts: 5
bisectBatchOnFunctionError: true
destinations:
onFailure:
type: sqs
arn:
Fn::GetAtt: [ RecordsDLQ, Arn ]
Yet another possibility is to provide a timestamp if we want to process records from a given point in time.
Pitfall #4: insufficient parallelization
Kinesis Data Stream consists of shards, and we pay for the number of them. Each shard can receive up to 1 MB or 1,000 records per second. However, the fact we have enough throughput to ingest messages into the shard doesn’t mean we can read and process them at the same rate.
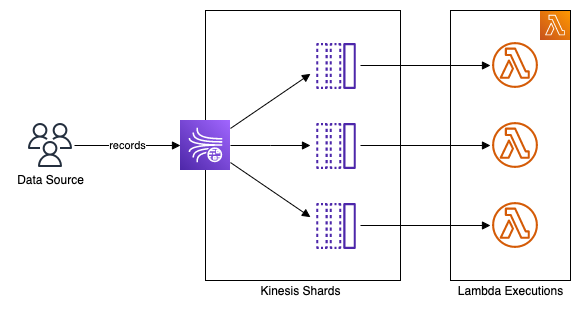
Let’s say each shard receives 100 new records every second. It’s way below the limit. But if our Lambda function takes 2 seconds to process such an amount of data, we will be lagging more and more, unable to catch up.
At this point, you surely know there has to be a solution, or we wouldn’t be talking about it. And there is, not just one, but two.
The first one is to simply increase the number of shards on the Kinesis side. The number of Lambda executions will increase to match it as well. Of course, records need to have sufficiently varied partition keys to be split evenly into shards, and additional shards will cause additional charges.
The other solution is to use the parallelizationFactor property.
It enables processing messages from a single shard in up to 10 concurrent executions.
Despite reading from shard in parallel, the order of records with the same partition key is still maintained.
Thus, increasing parallelization allows safely processing a higher data volume without increasing the costs of Kinesis. However, the max total read throughput per shard still applies.
functions:
consumer:
name: ${self:custom.baseName}-consumer
handler: src/index.handler
events:
- stream:
type: kinesis
arn:
Fn::GetAtt: [ KinesisStream, Arn ]
startingPosition: LATEST
parallelizationFactor: 10
batchSize: 100
batchWindow: 5
maximumRetryAttempts: 5
bisectBatchOnFunctionError: true
destinations:
onFailure:
type: sqs
arn:
Fn::GetAtt: [ RecordsDLQ, Arn ]
Pitfall #5: unnoticed processing lag
As always, we should monitor our Lambda function for failures, timeouts, and throttles. We can do it directly in AWS by creating individual alarms for each of these metrics. Another option is to use Dashbird, which will monitor our function’s health out of the box without any additional configuration.
But when dealing with Kinesis, it’s not enough. Even if Lambda works correctly, that doesn’t mean the whole system runs smoothly. We may have more records incoming to the stream than we can process. There may be multiple reasons, like traffic spikes or increased latency of external service used by Lambda.
That’s why one of the most crucial Kinesis metrics to keep an eye on is the Iterator Age. It tells us how long the message was in the stream before the Lambda read it. The growing age of records is automatically detected and reported by Dashbird for all streams with no additional setup.
Pitfall #6: lack of stream monitoring
Iterator Age, while important, is not the only metric to monitor. There is also another reason for which the Lambda function may not be producing new results. And it’s very prosaic.
If the stream stops receiving new data, Lambda will have nothing to analyze and process. That often goes unnoticed, as it does not produce errors. When there is nothing to run, there is nothing to fail.
Fortunately, Dashbird provides insights and auto-detection of such scenarios as well. In addition to reporting read and write throttles or failing processing, it also alerts about abandoned streams with no new incoming data.

Dashbird Kinesis Stream write throttles chart
Conclusion and Bonus
We can process Kinesis Data Streams records easily with AWS Lambda functions. However, it’s essential to set this integration right. Otherwise, it can generate unnecessary costs and result in poor performance altogether. Besides that, monitoring as always plays a critical role in keeping services up and running.
There is also a bright side – a small bonus. When we learn how to work with Kinesis, most of our knowledge will also apply to handling DynamoDB Streams. We can utilize most of the configuration options and solutions mentioned above when the Lambda function processes change from DynamoDB.
Full code for the Serverless Framework configuration, Lambda function handler, and dummy records producer is available on GitHub:

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.