- My objection towards CDK
- The need for CDK
- Pros of CDK
- Reusable custom Constructs
- High-level Constructs
- Sensible defaults
- Utility functions
- Logic above CloudFormation
- Advantages over Serverless Framework plugins
- Multiple stacks support
- Built-in CI
- Construct Hub
- Cons of CDK
- One-at-the-time stacks deployment
- CodePipeline for the CI
- Low-value constructs in Construct Hub
- Conclusion
Until recently, I was skeptical about the AWS CDK. I believe in Infrastructure as Code (IaC), but with the “code” being YAML. But after using CDK in real projects, the amount of heavy lifting it does and the vast reduction of a boilerplate code changed my view.
I’m a long-time user and fan of the Serverless Framework, and it was my go-to tool for the IaC on AWS. It provides an abstraction layer on top of the CloudFormation, the AWS infrastructure provisioning service. I thought that with the Serverless Framework, building serverless projects is as straightforward as it can be.
Then, in July 2019, AWS released the CDK – Cloud Development Kit. Like Serverless Framework, it also uses CloudFormation under the hood. But contrary to the SF, in which the primary way to declare infrastructure is YAML, in CDK, you write code in one of the supported programming languages.
When others started adopting CDK, I didn’t jump on the hype train right away but kept looking from a distance. This changed in the past months.
My objection towards CDK
My biggest objection was the core trait of the CDK – declaring infrastructure in a programming language.
While YAML has its problems, I see it as an elegant and readable solution to define the configuration. And that includes infrastructure configuration.
On the other hand, it’s much easier to make a mess using a programming language, and that’s what I was afraid of. When you can use loops, if conditions, and any advanced language features, you can as easily define the infrastructure cleanly and concisely as make it a spaghetti code. And the infrastructure is the last place where I want to investigate step-by-step what the hell is happening through the code flow.
To sum up – I believe(d) that it’s much less likely to make the infrastructure definition unreadable with YAML than using a programming language.
The need for CDK
Then I started working on a new project that required the resources to be created based on the configuration files. During the deployment, multiple instances of Lambda functions and other resources had to be generated with different settings depending on the provided configuration.
Generating resources dynamically during deployment requires some higher-level logic. While you can use JavaScript/TypeScript instead of YAML to define resources in the Serverless Framework, the CDK, with code as the native way to declare infrastructure, seemed like an obvious choice.
If you already used CloudFormation or any IaC tool based on it (like Serverless Framework or SAM), the learning curve of CDK is flat. In a few weeks, I scaffolded the new project, finding out how much good there was in the CDK. Now, two projects later, the CDK is the default IaC framework for me.
Pros of CDK
The two most obvious pros of CDK are that you can utilize all the power of a programming language to define the infrastructure and that it uses CloudFormation under the hood.
With languages supported by the CDK – TypeScript, JavaScript, Python, Java, C#, and Go – you write the code in a familiar way. No more esoteric CloudFormation logic instructions in JSON or YAML. And, with the code completion in your IDE, no more checking the documentation for the exact name of every single parameter.
Equally important, CDK “synthesizes” the code into standard CloudFormation stacks and deploys them. Using CloudFormation, the stable and battle-tested (although slow) IaC system to perform the actual infrastructure management, CDK can focus on providing the best possible developer experience on top of it.
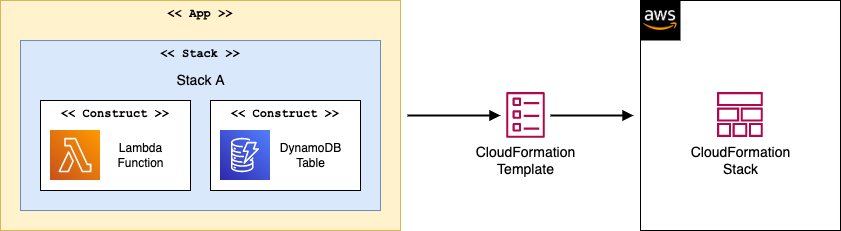
But what really convinced me were things I found only after I started working with the CDK.
Reusable custom Constructs
First and foremost, Constructs reusability.
Constructs are building blocks of the CDK. Like LEGO bricks, you can compose them to make larger, specialized Constructs. Then you can use those Constructs multiple times across the application to create many similar resources without repeating the configuration.
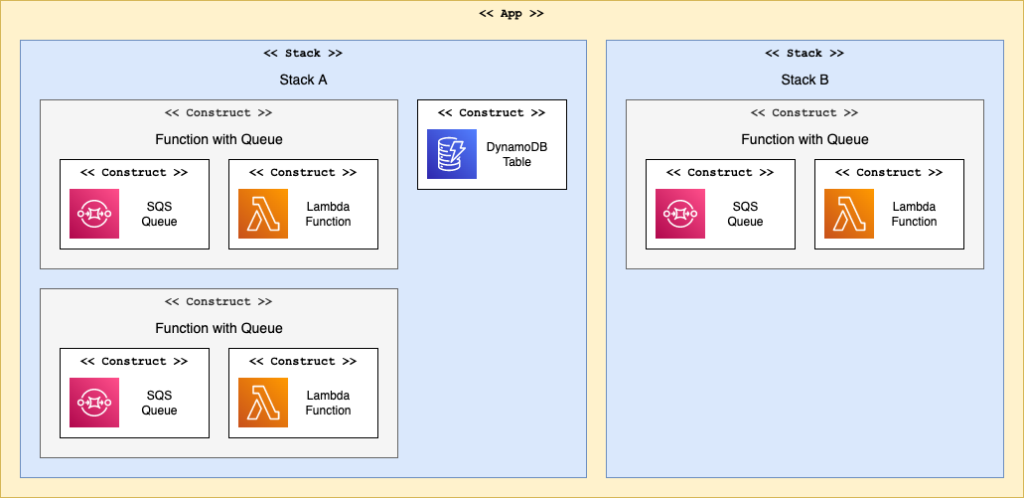
This is really powerful. The first thing I did was to create a custom Construct for a Node.js Lambda function, which included basic CloudWatch Alarms. This way, every function in my application is always properly monitored. Overriding the parameters of this custom Lambda Construct, I can customize alarm thresholds and function configuration where needed.
High-level Constructs
CDK comes with 3 “levels” of Constructs.
Level 1, or L1, are low-level Constructs that correspond directly to the CloudFormation resources.
Their names are prefixed with Cfn, like CfnBucket or CfnFunction. With them, you work with exactly the same structures as in raw CloudFormation, with the same parameters and behavior.
Nothing more, nothing less.
L2 Constructs, on the other hand, are smarter and provide higher-level API. They come with sensible defaults and reduce the required boilerplate code to the minimum. They also provide helper functions, for example, to set the IAM permissions.
L2 Constructs are the core of the CDK. Using them, you apply many best practices for setting up individual resources, like protecting access to the S3 Buckets. And since their API is an abstraction over the CloudFormation properties, it’s a lot more concise and readable.
This snippet creates a secured S3 Bucket and a Lambda function with an IAM Role granting read access to it, which translates to about 80 lines of L1 Constructs code or raw CloudFormation YAML:
const myBucket = new Bucket(this, 'MyBucket', {
encryption: BucketEncryption.S3_MANAGED,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED,
});
const myLambda = new NodejsFunction(this, 'MyLambda', {
entry: path.join(__dirname, 'src', 'index.ts'),
runtime: Runtime.NODEJS_16_X,
});
myBucket.grantRead(myLambda);
L3 Constructs, also called patterns, are even more abstract building blocks that include multiple resources. For example, with a single L3 Construct, you can create a Fargate service running on an ECS cluster behind an Application Load Balancer. Don’t make me count how many CloudFormation resources you need to define to set it up yourself…
Sensible defaults
I’ve mentioned it above, but let me emphasize this. L2 and L3 Constructs include sensible defaults that reduce the boilerplate and make the infrastructure safer, more robust, and closer to the best practices.
Examples include:
- S3 Buckets and DynamoDB tables having enabled “Retain” Deletion Policy by default to not loose production data in case of accidental stack removal,
- Node.js Lambda functions enabling connections reuse to optimize AWS SDK v2
Utility functions
Utility functions are a great help in L2 and L3 Constructs.
The ones you will most often come across are the IAM permissions helpers.
Instead of laboriously defining IAM policies, you can glue access between Constructs with grant*() functions.
const myLambda = new NodejsFunction(this, 'MyLambda', {
entry: path.join(__dirname, 'src', 'index.ts'),
runtime: Runtime.NODEJS_16_X,
});
myS3Bucket.grantRead(myLambda);
myDynamoDBTable.grantReadWriteData(myLambda);
But IAM helpers are not all. Few other examples include:
Function.metricError()to get a CloudWatch Metric for the Lambda function errors count that you can use to set up a CloudWatch Alarm,MappingTemplate.dynamoDbGetItem()to create an AppSync resolver mapping template to put an item to a DynamoDB Table,Arn.format()to build an ARN from the parts like the region, service name, and the resource name,- and many more.
Logic above CloudFormation
CloudFormation, used under the hood by the CDK, deals only with the infrastructure and is very strict about it. It takes the current state of the resources and modifies them to achieve the expected state.
But deployment often includes more than just creating cloud resources.
For example, you need to upload your application code, sometimes upload some assets to S3 buckets, or create an SSL certificate for the domain in the us-east-1 region for the CloudFront.
Those actions are outside of the CloudFormation scope.
Thankfully, they are not outside of the CDK scope.
For example, the Lambda Function Construct will bundle and upload your function code.
The S3 BucketDeployment Construct will put your website files in a bucket.
And DnsValidatedCertificate Construct will create an SSL certificate in any region you need.
Another neat built-in feature is the autoDeleteObjects parameter of the S3 Bucket Construct.
When set to true, it will empty the bucket on the stack removal, letting the bucket be deleted.
This is perfect for website hosting and short-living feature branch environments, where buckets do not contain valuable data.
Advantages over Serverless Framework plugins
You can achieve all of the above in the Serverless Framework with plugins. But the CDK has two advantages here.
Firstly, it’s all built-in. No additional dependencies to install and no problems with unmaintained and outdated plugins.
Secondly, everything is handled server-side (cloud-side?) by the custom resources triggered by CloudFormation lifecycle hooks. You run the stack deployment, and you don’t worry about uninterrupted internet connection during the SSL certificate creation and verification. Even better, you can delete the stack from the AWS Console, and it will trigger the bucket content removal, not only when you delete the stack using the CDK CLI.
In contrast, Serverless Framework plugins usually perform such actions through the AWS SDK calls from your local machine.
Multiple stacks support
Most of the projects I work on consist of multiple CloudFormation stacks. In CDK, you create an App, which may include numerous Stacks. Then, you can define dependencies between the stacks, and the CDK will take care of deploying them in the correct order.
The fact that multiple stacks are managed as a single application enables applying settings and making changes to the whole project in one place, without duplication. This includes setting tags or applying Aspects to all the resources in all the stacks.
/**
* Set RemovalPolicy DESTROY to LogGroups
* so they are removed on the stack removal, not kept indefinitely.
*/
class LogGroupRemovalPolicyAspect implements IAspect {
public visit(node: IConstruct): void {
if (node instanceof CfnLogGroup) {
node.applyRemovalPolicy(RemovalPolicy.DESTROY);
}
}
}
const app = new cdk.App();
Tags.of(app).add('projectName', 'mySecretProject');
Aspects.of(app).add(new LogGroupRemovalPolicyAspect());
Built-in CI
With CDK, you can create a Continuous Integration pipeline for the project. The pipeline, obviously using AWS CodePipeline, is quite clever. You deploy it once, and if you make and commit any changes to it, it will mutate itself before deploying your stacks.
Construct Hub
Constructs’ reusability makes them perfect for sharing. Construct Hub is a catalog of open-source Constructs built by AWS, AWS partners, and the community.
Among a variety of L3 Constructs, especially those three caught my eye:
- cdk-iam-floyd – IAM Policy generator with a fluent interface
- cdk-monitoring-constructs – CloudWatch Dashboard and Alarms for various AWS services
- CDK-SPA-Deploy – all you need to have a SPA website running
Cons of CDK
Obviously, I had to find some drawbacks. Otherwise, I would be even angrier that I only now convinced myself to CDK.
One-at-the-time stacks deployment
CDK runs on top of CloudFormation, which is famously slow. In a multi-stack application, you need to deploy stacks in parallel where possible to reduce the overall deployment time.
Unfortunately, at the moment, this is not possible with the CDK when deploying from your local machine. So you can take a (long) break every time you deploy the whole application. But this will hopefully be resolved soon with a –concurrency option.
CodePipeline for the CI
The built-in CI, while clever, is using the AWS CodePipeline. And if you have worked with the CodePipeline, you know it’s not the best CI out there.
The biggest issue I encountered is the impossibility of retrying individual failed stage deployments. The CDK splits stack deployments into creating CloudFormation Change Sets and executing them. If executing Change Set fails due to a conflict you then fix, it’s impossible to retry the given stage deployment without re-running the whole pipeline. This is because, when retrying the individual stage deployment, CodePipeline runs only the failed actions (the Change Set execution) and does not re-create the Change Sets first.
Also, if you want to notify your GitHub repository of the pipeline execution result, you need to implement the webhook call yourself. This is yet another example of how great the AWS CodePipeline is.
Of course, you don’t have to use built-in CDK pipelines. Instead, you can script your own deployment on any CI/CD platform you want.
Low-value constructs in Construct Hub
I’ve described the Construct Hub above as a library of high-level CDK Constructs. At the moment it contains over 1000 packages.
That sounds great, but many of them are L3 patterns which are, in my opinion, rather low value.
For example, LambdaToSqs
and SqsToLambda
Constructs integrate just a Lambda writing or reading from the SQS queue.
Maybe it’s just me, but it seems a lot like the is-even
package – the benefits are too small to justify installing a dependency instead of doing it by yourself.
But maybe I’m wrong.
Conclusion
While I still find the Serverless Framework awesome for simpler use cases, I discovered that CDK is the best fit for larger projects. With it, you can reduce the boilerplate to the minimum. Declaring infrastructure is faster with high-level Constructs, code completion, sensible defaults, and utilities. And it’s easier to keep high-quality and unified configuration with reusable Constructs.

- 📨 algorithm-independent information about new posts
- 📘 my ebook about Serverless on AWS
- ✅ zero spam

Unsubscribe anytime.
Unsubscribe anytime.